이번 포스팅은 Transformer를 이해하기 전에 꼭 필요한 개념인 어텐션(Attention)에 대한 내용을 정리했다.
1. Attention이란?
어텐션이란 저번 포스팅에서 언급했던 RNN와 LSTM의 문제점인 장기 의존성 문제를 해결하기 위해 등장한 개념이다.
LSTM은 RNN의 장기 의존성 문제 완화를 위해 Gate 구조를 도입해서 cell state를 통해 정보가 유지될 수 있게 했지만, 문장이 길면 정보가 희미해진다는 한계는 여전히 있었는데, 이 문제를 해결하기 위해 개발된 것이 어텐션(Attention)이다.
어텐션은 입력 시퀀스 중 "현재 출력을 하는 데 있어서 더 중요하다고 판단되는 부분"에 집중하게 만드는 방식이다.
어텐션은 입력을 Query, Key, Value 세 가지로 나누어 계산한다.
Query (Q)
- 지금 생성할 단어가 무엇에 집중할 지 질문
- 디코더가 지금 생성할 단어의 hidden state
Key (K)
- 각 단어가 가진 정보의 성질
- 인코더의 각 단어별 hidden state
Value (V)
- 실제 전달되는 정보 (attention 결과로 가중합될 값)
- 인코더의 각 단어별 hidden state (보통 Key와 동일하다.)
Q와 K의 유사도(내적)을 계산해 "얼마나 주의할지(attention score)"를 정하고, 그 가중치를 V에 적용해 가중합(weighted sum)한다.
어텐션의 종류에는 여러 가지가 있는데, 아래의 순서로 진행하겠다.
- Dot product attention
- Scaled dot product attention
- Self attention
- Multihead attention (이건 다음 포스팅에서 다룰 예정)
2. Dot product attention
가장 기본적인 형태의 어텐션으로 수식은 아래와 같다.


위의 그림에서의 Q는 하늘색으로 표시된 디코더의 hidden state (h11, h12) 이고,
K, V는 분홍색으로 표시된 인코더의 hidden state (h11, h12)이다.
(Q, K, V의 크기는 2라고 가정)
계산 과정
- Q와 K들을 내적해서, attention score(위 그림의 초록색 s) 벡터(S)를 구한다.
- S 벡터를 softmax layer에 넣어 각 score들을 확률값으로 매핑하고 동시에 정규화까지 진행한다.
- 그렇게 변환한 S를 V와 곱하고, 그 값들을 모두 더해주면(weighted sum) 최종 context vector가 완성된다.
- 완성된 context vector을 다음 LSTM의 input으로 주면, 위의 과정을 반복하며 새로운 단어와 다음 context vector을 생성해낸다.
3. Scaled dot product attention
위의 Dot product attention은 문제가 하나 있는데, Q와 K의 차원 수(d_k)가 커질수록 Attention score 값이 커져 softmax가 불안정해지고, 기울기 소실의 위험이 증가하게 된다 (d_k는 임베딩 차원 수).
softmax가 불안정해지는 이유는?
d_k의 값이 커질수록 이 내적 값들의 분산이 커진다. 즉, Q와 K의 값들이 평균 0, 분산 1이라고 해도 차원이 너무 커지면 내적 결과는 평균=0, 분산=d_k가 되는데, 이 결과를 softmax에 넣으면 확률값이 0 또는 1에 쏠리게 되기 때문에 불안정해진다는 것이다.
이를 해결하기 위해 dot product attention 과정에서 attention score 값을 √d_k로 나눠주는 계산을 추가한 것이 scaled dot product attention이다. 수식은 아래와 같다.

이 계산 과정을 추가하면 학습의 안정성이 높아지므로 transformer에서도 해당 방법을 사용한다.
4. Self attention
지금까지의 어텐션은 시퀀스 데이터를 순차적으로 처리하며 입력 시퀀스와 출력 시퀀스 간의 주목해야 할 단어를 찾는 어텐션이었다면, (인코더와 디코더)
Self attention은 입력 시퀀스 안에서의 모든 단어가 서로를 참조하며 단어 간의 관계성을 파악하는 방식이다.


그러므로 셀프 어텐션의 Q, K, V는 모두 입력 시퀀스에서 결정된다.
또한 Q, K, V 모두 동일한 입력 X를 선형변환을 적용해서 구한다.
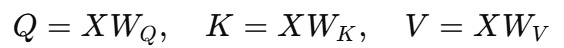
- X: 입력 시퀀스 벡터
- W: 학습 가능한 가중치이며, 처음에는 랜덤값으로 초기화해서 사용한다.
그 이후의 계산 과정은 이전 단계의 어텐션들과 같다.
- 입력 X → 선형 변환 → Q, K, V
- Q·Kᵀ → attention score
- score / √d_k → softmax → attention weights
- attention weights × V → context vector
여기서 가중치 행렬 W는 역전파 과정을 통해 업데이트된다.
transformer에서는 이 셀프 어텐션을 여러 개의 병렬 구조로 사용하는 Multihead attention을 사용한다.
(다음 포스팅에서 다룰 예정)
회고
한 번에 여러 어텐션들을 공부하니 처음에는 뭐가 뭔지 헷갈렸었다.
근데 이 어텐션들의 관계(소속?)와 발전 흐름을 파악하니 전체적인 흐름을 이해할 수 있었다.
처음에는 각각 서로 다른 어텐션인줄 알았지만 공부해보니 결국에는 Q, K, V을 구하고 이것으로 계산하는 과정도 약간의 차이를 제외하면 거의 동일해서 이해하기 수월했다.
참고한 영상
https://www.youtube.com/watch?v=cu8ysaaNAh0
'AI > NLP' 카테고리의 다른 글
| [11/05] 아이펠 리서치 15기 TIL | Transformer 구현 (0) | 2025.11.15 |
|---|---|
| [10/31] 아이펠 리서치 15기 TIL | Transformer (0) | 2025.11.05 |
| [10/26] 아이펠 리서치 15기 TIL | RNN & LSTM (1) | 2025.10.26 |
| [10/25] 아이펠 리서치 15기 TIL | 임베딩(Embedding) (1) | 2025.10.25 |
| [10/24] 아이펠 리서치 15기 TIL | 토큰화 (Tokenization): Subword Tokenization (0) | 2025.10.25 |



