오늘은 임베딩이 무엇인지, 어떤 알고리즘과 모델이 있는지 공부했다.
대표적으로 N-gram, TF-IDF, Word2Vec, FastText 등에 대해 작성해 보겠다.
1. 임베딩 (Embedding)
컴퓨터는 텍스트 자체를 이해할 수 없다.
그러므로 텍스트를 숫자로 변환하는 과정이 필요한데, 이것을 임베딩이라고 한다.
흔히 알고 있는 원-핫 인코딩도 텍스트 벡터화 중 하나이다.
이 방법은 쉽고 간단하다는 장점이 있지만, 벡터가 sparse하고 corpus가 커질수록 그만큼 벡터의 차원도 커지므로 필요 리소스 증가, 차원의 저주 위험 등의 단점도 있다.
또한, 텍스트의 유사성을 판단하지 못 하는데, 예를 들면 "i scream for ice cream", "ice cream for i scream" 두 문장에 원-핫 인코딩을 적용하면 둘 다 [1, 1, 1, 1, 1] 벡터로 반환된다.
이러한 문제를 해결하기 위해 Word2Vec, fastText처럼 단어의 의미를 학습해 표현하는 워드 임베딩(Word Embedding) 기법을 사용한다.
워드 임베딩 기법은 단어를 고정된 길이의 실수 벡터로 표현하는 방법으로, 토크나이저가 텍스트를 토큰으로 분리하면 워드 임베딩은 각 토큰을 숫자 벡터로 바꿔주는 역할을 한다.
아래는 원-핫 인코딩과 워드 임베딩을 비교하는 예시이다.
가정: 10,000개의 단어 존재
# 원-핫 인코딩
'강아지' = [0, 0, ..., 1, ..., 0] (10,000차원)
→ 이 방식은 '강아지'와 '고양이'의 관계 또는 '강아지'와 '컴퓨터'의 관계를 수학적으로 구분할 수 없다.
→ 그 이유는? 모든 단어 간의 거리가 동일하기 때문# 워드 임베딩
모든 단어를 100~300차원 정도의 Dense Vector로 표현한다.
'강아지' = [0.2, -0.4, 0.7, ..., 0.1]
'고양이' = [0.3, -0.5, 0.6, ..., 0.2]
'컴퓨터' = [0.9, 0.1, -0.8, ..., -0.5]
→ 이 벡터 공간에서는 '강아지'와 '고양이'는 서로 가까운 위치에, '컴퓨터'는 먼 위치에 존재한다.2. 언어 모델
2.1. N-gram
텍스트에서 N개의 연속된 단어 시퀀스를 하나의 단위로 취급하여 특정 단어 시퀀스가 등장할 확률을 추정한다.
N-gram 모델은 input을 하나의 토큰 단위로 분석하지 않고 N개의 토큰을 묶어서 분석한다.
N=1 이면 Unigram, N=2 이면 Bigram, N=3 이면 Trigram, N>=4 이면 N-gram이라고 한다.
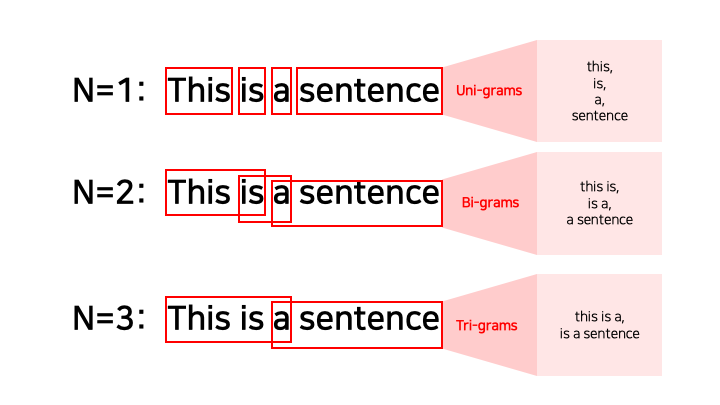

N-gram은 모든 토큰을 사용하지 않고 N-1개의 토큰만을 고려해 확률을 계산한다.
이게 무슨 말이냐?
N-gram은 특정 단어의 확률을 예측할 때, 그 단어 바로 앞에 나오는 (N-1)개의 단어만 본다.
즉, "다음 단어는 바로 직전의 (N-1)개 단어에만 영향을 받는다"고 단순히 가정하는 것인데, 이를 마르코프 가정(Markov Assumption)이라고 한다.
예시: "오늘 날씨가 정말 좋다"
이 문장에서 "좋다"라는 단어가 나올 확률은?
- Bigram(2-gram) 모델
- "좋다" 앞에 있는 1개(2-1)의 단어인 "정말"만 보고 "오늘", "날씨가"는 무시한다.
- P(좋다 | 정말)
- Trigram(3-gram) 모델
- "좋다" 앞에 있는 2개(3-1)의 단어인 "날씨가 정말"만 보고 "오늘"은 무시한다.
- P(좋다 | 날씨가, 정말)
위 Trigram의 확률 P(좋다 | 날씨가, 정말)의 계산 방법은 아래와 같다.
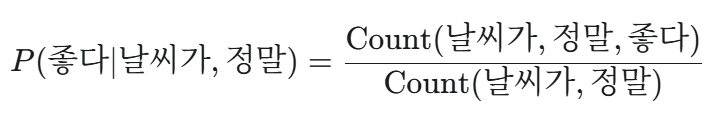
하지만, (N-1)개보다 더 앞에 있는 단어들은 확률 계산 시 완전히 무시하기 때문에 핵심 단어를 참고하지 못 할 수도 있다는 단점이 있다.
다음은 간단한 파이썬 코드와 NLTK 라이브러리를 이용해 N-gram을 구현하는 코드이다.
import nltk
def ngrams(sentence, n):
words = sentence.split()
ngrams = zip(*[words[i:] for i in range(n)])
return list(ngrams)
sentence = "안녕하세요 만나서 진심으로 반가워요"
# 직접 구현한 ngram
unigram = ngrams(sentence, 1)
bigram = ngrams(sentence, 2)
trigram = ngrams(sentence, 3)
print(unigram)
print(bigram)
print(trigram)
# NLTK에서 지원하는 ngram
unigram = nltk.ngrams(sentence.split(), 1)
bigram = nltk.ngrams(sentence.split(), 2)
trigram = nltk.ngrams(sentence.split(), 3)
print(list(unigram))
print(list(bigram))
print(list(trigram))# 직접 구현한 1,2,3-gram
[('안녕하세요',), ('만나서',), ('진심으로',), ('반가워요',)]
[('안녕하세요', '만나서'), ('만나서', '진심으로'), ('진심으로', '반가워요')]
[('안녕하세요', '만나서', '진심으로'), ('만나서', '진심으로', '반가워요')]
# NLTK에서 지원하는 1,2,3-gram
[('안녕하세요',), ('만나서',), ('진심으로',), ('반가워요',)]
[('안녕하세요', '만나서'), ('만나서', '진심으로'), ('진심으로', '반가워요')]
[('안녕하세요', '만나서', '진심으로'), ('만나서', '진심으로', '반가워요')]2.2. TF-IDF (Term Frequency-Inverse Document Frequency) (모델 아님)
TF-IDF는 수많은 문서들 중에서, 이 문서의 핵심 키워드(중요한 단어)가 무엇인지를 알아내는 방법이다.
즉, 이 문서에서는 자주 등장하지만, 다른 문서들에서는 잘 안 나오는 단어가 있다면 그 단어의 중요도가 높다고 평가하는 방법이다.
TF-IDF는 TF와 IDF 값을 곱해서 계산한다.
1. TF (Term Frequency): 단어 빈도 (이 문서 안에서 이 단어가 얼마나 자주 나왔는지)
- 특정 단어가 한 문서 내에서 많이 등장할수록, 그 단어는 그 문서와 관련성이 높다.
- (문서 내 특정 단어 등장 횟수) / (문서의 총 단어 수)
- 또는 해당 단어의 등장 횟수 자체
2. IDF (Inverse Document Frequency) : 역 문서 빈도 (이 단어가 다른 문서들에서 얼마나 희귀한지)
- 많은 문서에 공통적으로 등장하는 흔한 단어는 중요도를 낮추고, 특정 문서에만 드물게 등장하는 단어는 중요도를 높인다.
- log( (전체 문서 수) / (이 단어를 포함한 문서 수) )
아래는 사이킷런 라이브러리를 이용한 TF-IDF 계산 코드이다.
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
"That movie is famous movie",
"I like that actor",
"I don’t like that actor"
]
tfidf_vectorizer = TfidfVectorizer()
tfidf_vectorizer.fit(corpus)
tfidf_matrix = tfidf_vectorizer.transform(corpus)
# 또는 fit_transorm 메서드로 학습과 변환 동시 수행
# tfidf_matrix = tfidf_vectorizer.fit_transform(corpus)
print(tfidf_matrix.toarray())
print(tfidf_vectorizer.vocabulary_)[
[0. 0. 0.39687454 0.39687454 0. 0.79374908 0.2344005 ]
[0.61980538 0. 0. 0. 0.61980538 0. 0.48133417]
[0.4804584 0.63174505 0. 0. 0.4804584 0. 0.37311881]
]
{'that': 6, 'movie': 5, 'is': 3, 'famous': 2, 'like': 4, 'actor': 0, 'don': 1}각 단어는 고유 인덱스를 가지며, 등장 순으로 자동 인덱싱된다.
- "movie"는 첫 문장에만 등장 → IDF가 높음 → TF-IDF도 큼 (0.7937)
- "that"은 모든 문장에 등장 → IDF가 낮음 → TF-IDF 작음 (0.2344, 0.4813, 0.3731)
2.3. Word2Vec
단어 간의 유사성을 측정하기 위해 분포 가설(Distributional Hypothesis) 기반으로 개발된 모델이다.
분포 가설이란 같은 문맥에서 함께 자주 나타나는 단어들은 서로 유사한 의미를 가질 가능성이 높다는 가정이다.
주요 학습 방식에는 CBoW, Skip-gram 두 가지 모델이 있다.
2.3.1. CBoW
CBoW(Continuous Bag of Words)란 주변 단어(context)들로 중심 단어(target)를 예측하는 방식을 사용한다.
중심 단어를 맞추기 위해 몇 개의 주변 단어를 고려할지를 정해야 하는데, 이 범위를 Window라고 한다.
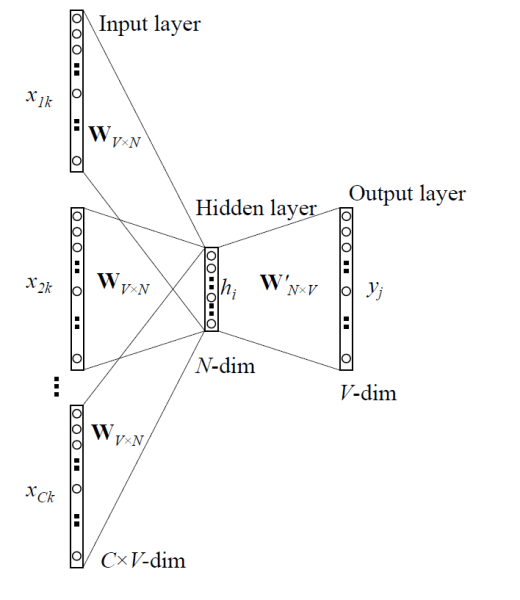
예시:
text = ["A", "quick", "brown", "fox", "jumps", "over"]
Window Size = 2
Target = "brown"
Context = ["A", "quick", "fox", "jumps"]- Context 단어들의 벡터를 각각 입력받는다.
- 이 벡터들을 평균내거나 더해서 하나의 벡터로 만든다.
- 이 평균 벡터를 은닉층으로 보낸다.
- 출력층에서 Target 단어인 "brown"일 확률이 높아지도록 학습한다.
2.3.2. Skip-gram
Skip-gram은 CBoW와 반대로 중심 단어를 입력으로 받고 주변 단어를 예측하는 모델이다.

예시: (위와 같음)
text = ["A", "quick", "brown", "fox", "jumps", "over"]
Window Size = 2
Target = "brown"
Context = ["A", "quick", "fox", "jumps"]- Target 단어 "brown"의 벡터를 입력받는다.
- 은닉층으로 보낸다.
- 출력층에서 Context 단어들이 각각 등장할 확률이 높아지도록 학습한다.
두 모델의 출력층은 모두 소프트맥스 연산을 하는데, 소프트맥스 연산은 모든 단어를 대상으로 내적 연산을 하기 때문에 corpus의 크기가 커지면 단어 사전의 크기도 커지므로 학습 속도가 느려지는 단점이 있다.
이때, 계층적 소프트맥스와 네거티브 샘플링 기법을 적용해 학습 속도가 느려지는 문제를 완화할 수 있다.
2.3.3. 계층적 소프트맥스
계층적 소프트맥스(Hierarchical Softmax)는 출력층을 이진 트리(Binary tree) 구조로 표현해 연산한다.
이때 자주 등장하는 단어일수록 트리의 상위 노드에 위치하고, 그렇지 않을수록 하위 노드에 배치된다.
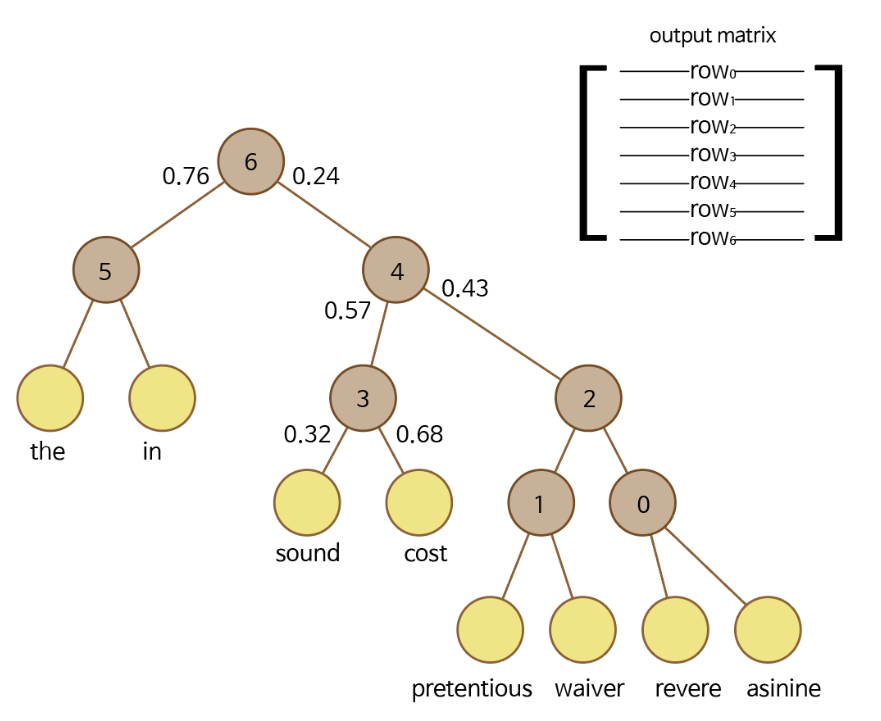
전체 어휘기 50,000개라고 가정하면, 출력층에서 50,000개 중 정답을 맞혀야 한다.
소프트맥스는 50,000개의 확률을 모두 계산하고 정규화까지 해야하는데, 매우 비효율적이다.
반면, 계층적 소프트맥스는 정답 단어를 찾기 위해 50,000번의 계산을 하는 대신, 트리의 루트(root)로부터 정답 단어(leaf node)까지 내려가는 경로를 찾는다.
이럴 경우 각 노드에서 왼쪽/오른쪽 중 어디로(이진 분류) 갈지만 결정하면 되기 때문에 50,000번에서 16번까지 대폭 줄어든다.
leaf node에 도착하면 경로의 모든 확률을 곱해서 그 단어가 나올 확률을 계산하고, 그 경로에 포함된 노드의 벡터만 최적화하면 되는 구조이다.
2.3.4. 네거티브 샘플링
네거티브 샘플링(Negative Sampling, NEG)은 가장 널리 쓰이는 방식이자 Word2Vec 모델에서 사용하는 확률적인 샘플링 기법으로, 전체 단어 집합에서 일부 단어를 샘플링하여 오답 단어로 사용한다.
계층적 소프트맥스와 마찬가지로 이진 분류 문제로 바꾸는데, 이 단어가 정답(Positive)인지 오답(Negative)인지 정하는 문제로 바꾼다.
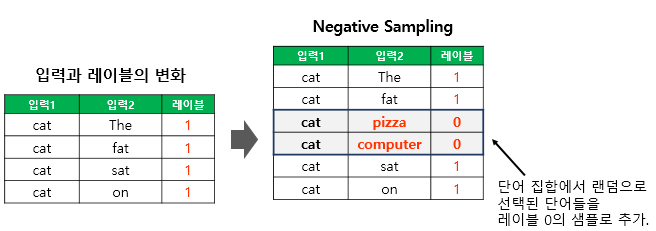
학습 과정은 아래와 같다.
- 중심 단어 'brown'과 실제 주변 단어 'fox' (Positive Sample)를 가져오고, ('brown', 'fox') 쌍의 점수는 1 (정답)이 되도록 학습한다.
- 어휘 목록에서 'fox'가 아닌 오답 단어(Negative Samples)를 k개 무작위로 뽑는다. (예: 'apple', 'car', 'music', k=3)
- ('brown', 'apple') 쌍의 점수는 0 (오답)이 되도록 학습.
- ('brown', 'car') 쌍의 점수는 0 (오답)이 되도록 학습.
- ('brown', 'music') 쌍의 점수는 0 (오답)이 되도록 학습.
(1+k)개의 출력만 계산하면 되므로 이 방법 또한 50,000번의 계산에서 1+k번으로 연산량이 대폭 줄어든다.
2.4. fastText
fastText는 Word2Vec와 유사하지만, Word2Vec의 OOV 문제를 완화한 모델이다.
fastText는 OOV 문제를 어떻게 완화했을까?
Word2Vec이 단어를 통째로 하나로 보는 방식이라면, fastText는 n-gram을 사용해 단어를 서브워드로 나눠서 학습한다.
예를 들면, Word2Vec은 "apple"을 하나의 단어로 본다면, fastText는 아래와 같은 문자 단위 n-gram의 집합으로 본다.
N은 3이라고 가정하고,
단어의 시작과 끝을 '<', '>'로 표시하고 나누면
- <ap
- app
- ppl
- ple
- le>
- apple (원래 단어도 포함)
즉, apple이라는 단어를 [<ap, app, ppl, ple, le>, <apple>]로 본다.
이 상태에서 Word2Vec과 같은 방식(Skip-gram 또는 CBoW)으로 학습한다.
단, Word2Vec이 "apple"이라는 단어 벡터 1개만 업데이트 한 것과 다르게 위의 단어 집합에 포함된 모든 서브워드 벡터들을 업데이트한다.
학습이 끝나면 "apple"이라는 단어의 최종 벡터는 모든 서브워드 벡터들의 합(또는 평균)으로 계산한다.
이 방식의 장점은 OOV 문제를 해결한다는 것이다.
Word2Vec은 지금 "apple"만 학습된 상태이므로 "apples"는 OOV로 보낼 것이다.
반면, fastText는 서브워드 벡터들을 합쳐서 "apples" 벡터를 바로 만들어내고, 이 벡터는 "apple" 벡터와 매우 유사할 것이다.
→ OOV 해결
이러한 방식 덕분에 fastText는 오타나 신조어에도 유연하게 대처할 수 있다.
이 모든 방법들을 포함한 N-gram, TF-IDF, Word2Vec, fastText의 구현 코드는 아래에서 확인할 수 있습니다.
https://github.com/choiwonjini/AIFFEL_practice/blob/main/NLP/2_embedding_models.ipynb
AIFFEL_practice/NLP/2_embedding_models.ipynb at main · choiwonjini/AIFFEL_practice
Contribute to choiwonjini/AIFFEL_practice development by creating an account on GitHub.
github.com
회고
내용은 재미있고 너무 어렵지도 않았다(물론 처음 봤을 때는 고민을 많이 했다).
그런데 문제는,,,
저저번 포스팅부터 시작한 토큰화부터 다음 포스팅에서 다룰 RNN까지의 모든 내용이 단 이틀치 과정이라는 것이다,,,
원래 23, 24일에 모두 끝내야 하는 게 맞는데, RNN은 아직 시작도 못 했다.
책 정독, 블로그 작성, 코드 실습까지 모두 하려니 주말을 다 써도 시간이 너무 부족하다.
더 열심히 해보자💪
'AI > NLP' 카테고리의 다른 글
| [10/31] 아이펠 리서치 15기 TIL | Transformer (0) | 2025.11.05 |
|---|---|
| [10/29] 아이펠 리서치 15기 TIL | Attention (0) | 2025.11.01 |
| [10/26] 아이펠 리서치 15기 TIL | RNN & LSTM (1) | 2025.10.26 |
| [10/24] 아이펠 리서치 15기 TIL | 토큰화 (Tokenization): Subword Tokenization (0) | 2025.10.25 |
| [10/23] 아이펠 리서치 15기 TIL | 토큰화 (Tokenization): 형태소 분석, 품사 태깅 (0) | 2025.10.23 |

