Google Analytics란?
Google Analytics는 구글에서 제공하는 웹 및 모바일 앱의 트래픽과 사용자 행동을 분석하는 대표적인 웹 분석 도구이다. 웹사이트나 앱에 제공되는 자바스크립트 트래킹 코드를 삽입하면, 방문자가 사이트에 접속할 때마다 그 행동(페이지 조회, 세션 지속 시간, 이탈률, 전환 등)을 자동으로 기록하고, 이 데이터를 기반으로 다양한 보고서를 생성한다.
BigQuery란?
빅쿼리(BigQuery)는 구글 클라우드 플랫폼에서 제공하는 서버리스 데이터 웨어하우스 서비스이다. 별도의 인프라 관리 없이, SQL을 통해 페타바이트(PB) 규모의 대용량 데이터를 빠르게 저장, 분석, 쿼리할 수 있도록 설계되어 있다.
AARRR 분석이란?
AARRR은 사용자의 서비스 이용흐름을 기반으로 고객 획/ 활성화/ 유지/ 수익/ 추천 이라는 5가지 카테고리를 정의하고 각 카테고리에서 핵심이 되는 지표를 발굴하고 이를 측정/ 개선하는 지표관리 방법론이다.
- Acquisition (획득):
고객이 어떻게 해당 서비스나 제품을 알게 되었는지, 즉 유입 경로(검색, 미디어, 광고 등)를 분석. - Activation (활성화):
첫 방문 후 고객이 긍정적인 경험을 했는지 평가. 예를 들어, 회원 가입, 첫 구매, 앱 내 첫 행동 등이 이에 해당 됨. - Retention (유지):
고객이 제품이나 서비스를 반복적으로 이용하는지를 측정. 즉, 초기 경험 후 얼마나 많은 고객이 돌아오는지를 분석. - Revenue (수익):
고객으로부터 얼마나 수익을 창출할 수 있는지를 파악. 구매, 구독, 광고 클릭 등의 수익 창출 지표를 포함. - Referral (추천):
기존 고객이 다른 사람에게 제품이나 서비스를 추천하는지, 즉 자연스러운 입소문 효과를 분석.
이번 포스팅에서는 AARRR의 다섯 번째 순서인 Referral (추천) 단계에 대해 분석할 것이다.
Referral (추천)
사용자들이 우리 서비스를 주변 지인에게 소개/ 추천하는가?
즉, 서비스를 이용한 고객이 만족하여 자발적 바이럴 및 공유를 일으키는 것을 의미한다.
해당 단계는 충성도가 높은 고객들만 추천행동을 하기에 퍼널 내 가장 좁은 위치다.
이번 단계에서 수행할 분석
- GA는 추천 발송 데이터가 존재하지 않기 때문에, 이번 분석에서는 추천으로 유입된 '추천 유입 유저' 그룹과 추천으로 유입되지 않은 '비추천 유입 유저' 그룹 간에 차이를 분석할 것이다.
- 추천 / 비추천 유입 고객 그룹의 방문당 평균 수익(RPV)에 차이가 있는지 확인하기 위해 t-test 수행
- 추천 / 비추천 유입 고객 그룹 각각 퍼널의 전환율, 이탈율 비교 분석
추천 / 비추천 유입 고객별 수익 비교 분석
추천 / 비추천 유입 유저의 트래픽과 RPV
- 구매 이력이 있는 유저들을 대상으로 분석했다.
1. 추천 유입 유저
# 추천 유입 고객 트래픽 분석 쿼리
query = f"""
SELECT
COUNT(*) AS total_sessions,
SUM(IF(totals.pageviews = 1, 1, 0)) AS bounced_sessions,
SUM(IF(totals.pageviews = 1, 1, 0)) / COUNT(*) AS bounce_rate,
AVG(totals.timeOnSite) AS avg_session_duration,
AVG(totals.pageviews) AS avg_pageviews,
SUM(totals.transactionRevenue) / 1000000 AS total_revenue, -- 해당 변수는 마이크로 단위이므로 1,000,000으로 나눠야 함
SUM(totals.transactionRevenue) / 1000000 / COUNT(*) AS rpv -- 방문당 평균 수익(RPV, Revenue per Visit)
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
trafficSource.medium = 'referral'
AND _TABLE_SUFFIX BETWEEN '20160801' AND '20170801'
AND totals.transactionRevenue > 0
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_referral_traffic = query_job.to_dataframe()
# 결과 출력
df_referral_traffic
2. 비추천 유입 유저
# 비추천 유입 고객 트래픽 분석 쿼리
query = f"""
SELECT
COUNT(*) AS total_sessions,
SUM(IF(totals.pageviews = 1, 1, 0)) AS bounced_sessions,
SUM(IF(totals.pageviews = 1, 1, 0)) / COUNT(*) AS bounce_rate,
AVG(totals.timeOnSite) AS avg_session_duration,
AVG(totals.pageviews) AS avg_pageviews,
SUM(totals.transactionRevenue) / 1000000 AS total_revenue, -- 해당 변수는 마이크로 단위이므로 1,000,000으로 나눠야 함
SUM(totals.transactionRevenue) / 1000000 / COUNT(*) AS rpv -- 방문당 평균 수익(Revenue per Visit, RPV)
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
trafficSource.medium != 'referral'
AND _TABLE_SUFFIX BETWEEN '20160801' AND '20170801'
AND totals.transactionRevenue > 0
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_not_referral_traffic = query_job.to_dataframe()
# 결과 출력
df_not_referral_traffic
위의 결과를 비교해보니, 평균 세션 지속 시간과 RPV 모두 추천 유입 유저가 비추천 유입 유저보다 근소하게 높다는 것을 알 수 있다.
하지만 이 결과가 우연에 의한 것인지, 아니면 정말로 통계적으로 유의미한 차이가 있는지 알아보기 위해 t-검정을 시행할 필요가 있다.
3. t-검정
import scipy.stats as stats
# Referral vs Non-Referral 그룹화
df_referral = df_tmp[df_tmp['medium'] == 'referral']
df_non_referral = df_tmp[df_tmp['medium'] != 'referral']
# 방문당 평균 수익(RPV) 계산
df_referral_rpv = df_referral.groupby('fullVisitorId')['revenue'].sum()
df_non_referral_rpv = df_non_referral.groupby('fullVisitorId')['revenue'].sum()
# t-검정 수행 (독립표본 t-검정)
t_stat, p_value = stats.ttest_ind(df_referral_rpv, df_non_referral_rpv, equal_var=False) # Welch's t-test
# 결과 출력
print(f"t-통계량: {t_stat:.4f}")
print(f"p-값: {p_value:.4f}")t-검정 결과 p-value가 0.9531로 매우 크게 나왔다.
따라서 두 그룹의 RPV의 차이는 통계적으로 유의하지 않다고 할 수 있다.
그렇다면, 이제 두 그룹의 구체적인 퍼널을 알아보자.
추천 / 비추천 그룹별 퍼널 분석
1. 각 단계별 세션 수 산출
(1) 추천 유입 유저
# 추천 유입 유저들의 단계별 세션 수 분류 쿼리 작성
query = f"""
SELECT
h.eCommerceAction.action_type AS action,
COUNT(*) AS count
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`,
UNNEST(hits) AS h
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170801'
AND h.eCommerceAction.action_type IN ('1', '2', '3', '5', '6')
AND trafficSource.medium = 'referral'
GROUP BY
action
ORDER BY
count DESC
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_ref_funnels = query_job.to_dataframe()
# action 명칭 수정
df_ref_funnels['action'] = ['Product list', 'Product detail page', 'Add to cart', 'Check out', 'Completed purchase']
# 결과 출력
df_ref_funnels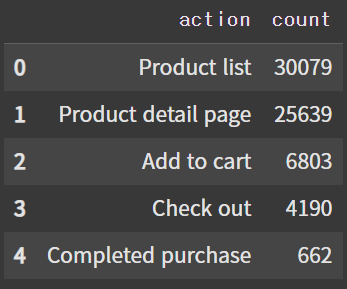
(2) 비추천 유입 유저
# 비추천 유입 유저들의 단계별 세션 수 분류 쿼리 작성
query = f"""
SELECT
h.eCommerceAction.action_type AS action,
COUNT(*) AS count
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`,
UNNEST(hits) AS h
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170801'
AND h.eCommerceAction.action_type IN ('1', '2', '3', '5', '6')
AND trafficSource.medium != 'referral'
GROUP BY
action
ORDER BY
count DESC
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_not_ref_funnels = query_job.to_dataframe()
# action 명칭 수정
df_not_ref_funnels['action'] = ['Product list', 'Product detail page', 'Add to cart', 'Check out', 'Completed purchase']
# 결과 출력
df_not_ref_funnels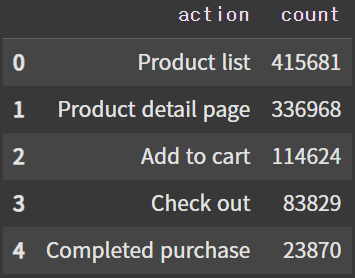
2. 그룹별 전환율(Conversion Rate) & 이탈률(Bounce Rate)
(1) 추천 유입 유저
conversion_rate = [100]
for i in range(0,4):
conversion_rate.append(round((df_ref_funnels['count'].iloc[i+1]/df_ref_funnels['count'].iloc[i])*100, 2))
df_ref_funnels['conversion rate'] = conversion_rate
df_ref_funnels['Bounce rate'] = np.repeat(100, 5) - np.array(conversion_rate)
df_ref_funnels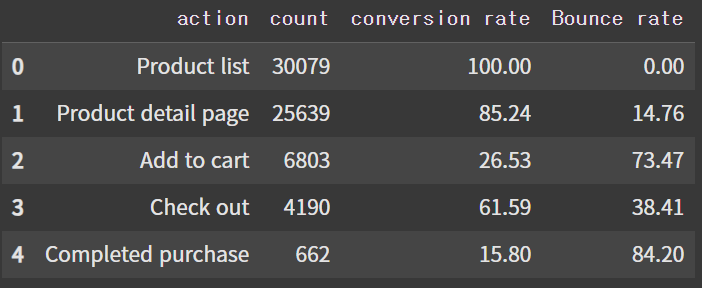
(2) 비추천 유입 유저
conversion_rate = [100]
for i in range(0,4):
conversion_rate.append(round((df_not_ref_funnels['count'].iloc[i+1]/df_not_ref_funnels['count'].iloc[i])*100, 2))
df_not_ref_funnels['conversion rate'] = conversion_rate
df_not_ref_funnels['Bounce rate'] = np.repeat(100, 5) - np.array(conversion_rate)
df_not_ref_funnels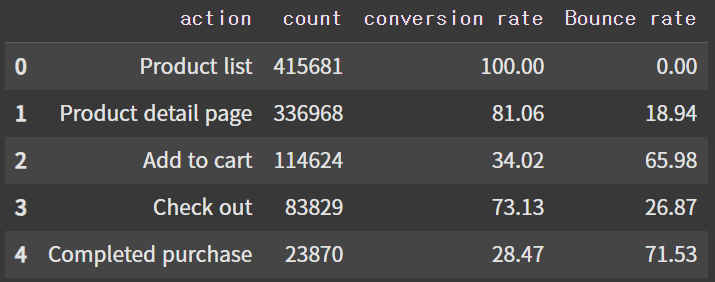
3. 두 그룹 간의 전환율 차이는 유의미할까?
두 그룹 간의 전환율 차이가 유의미한지 검정하기 위해 유의수준 5%에서 양비율 Z-검정을 시행해보겠다.
양비율 Z-검정(Two-Proportion Z-Test)
- 두 집단의 비율 차이를 검정하는데 사용
- 두 집단의 평균 차이를 검정하는 t-test와는 다른 검정법
# Product list -> Product detail page
prop.test(c(85.24, 81.06), c(100, 100), correct=F)
# X-squared = 0.62353, df = 1, p-value = 0.4297
# Product detail page -> Add to cart
prop.test(c(26.53, 34.02), c(100, 100), correct=F)
# X-squared = 1.3288, df = 1, p-value = 0.249
# Add to cart -> Check out
prop.test(c(61.59, 73.13), c(100, 100), correct=F)
# X-squared = 3.0285, df = 1, p-value = 0.08181
# Check out -> Completed purchase
prop.test(c(15.8, 28.47), c(100, 100), correct=F)
# X-squared = 4.6569, df = 1, p-value = 0.03093
결제 -> 구매완료 단계의 p-value만이 0.05 이하로 나왔으므로 해당 단계에서의 두 집단의 비율 차이가 유의한 것으로 보인다.
하지만 이것은 틀렸다.
해당 방법은 각 퍼널 단계별로 전환율 차이를 개별적으로 검정하기 때문에 다중 비교 문제가 발생하게 된다.
즉, 4개의 서로 다른 단계에 대해 각각 가설 검정을 수행하면 전체적으로 제1종 오류의 누적 위험이 증가하게 된다.
그렇다면 다중 비교 문제를 어떻게 해결할 수 있을까?
본페로니 교정(Bonferroni correction)
- 여러 개의 통계적 가설 검정을 동시에 수행할 때 발생할 수 있는 제1종 오류를 제어하기 위한 방법.
- 전체 유의수준을 일정 수준(예: 0.05)으로 유지하기 위해, 각 개별 검정에 사용하는 유의수준을 조정한다.
- 유의수준 alpha를 검정의 개수 m으로 나눈다.
유의수준 / 검정의 개수
- 0.05 / 4 = 0.0125
따라서 0.0125의 유의수준에서 다시 검정해보면, 모든 단계에서의 p-value가 0.0125보다 큰 것을 알 수 있다.
그러므로 본페로니 교정을 적용한 양비율 Z-검정은 모두 통계적으로 유의하지 않다고 할 수 있다.
정리하면, '추천/비추천 집단에 따라 전환율에 유의미한 차이가 없다.'라는 귀무가설을 채택한다.
4. 시각화
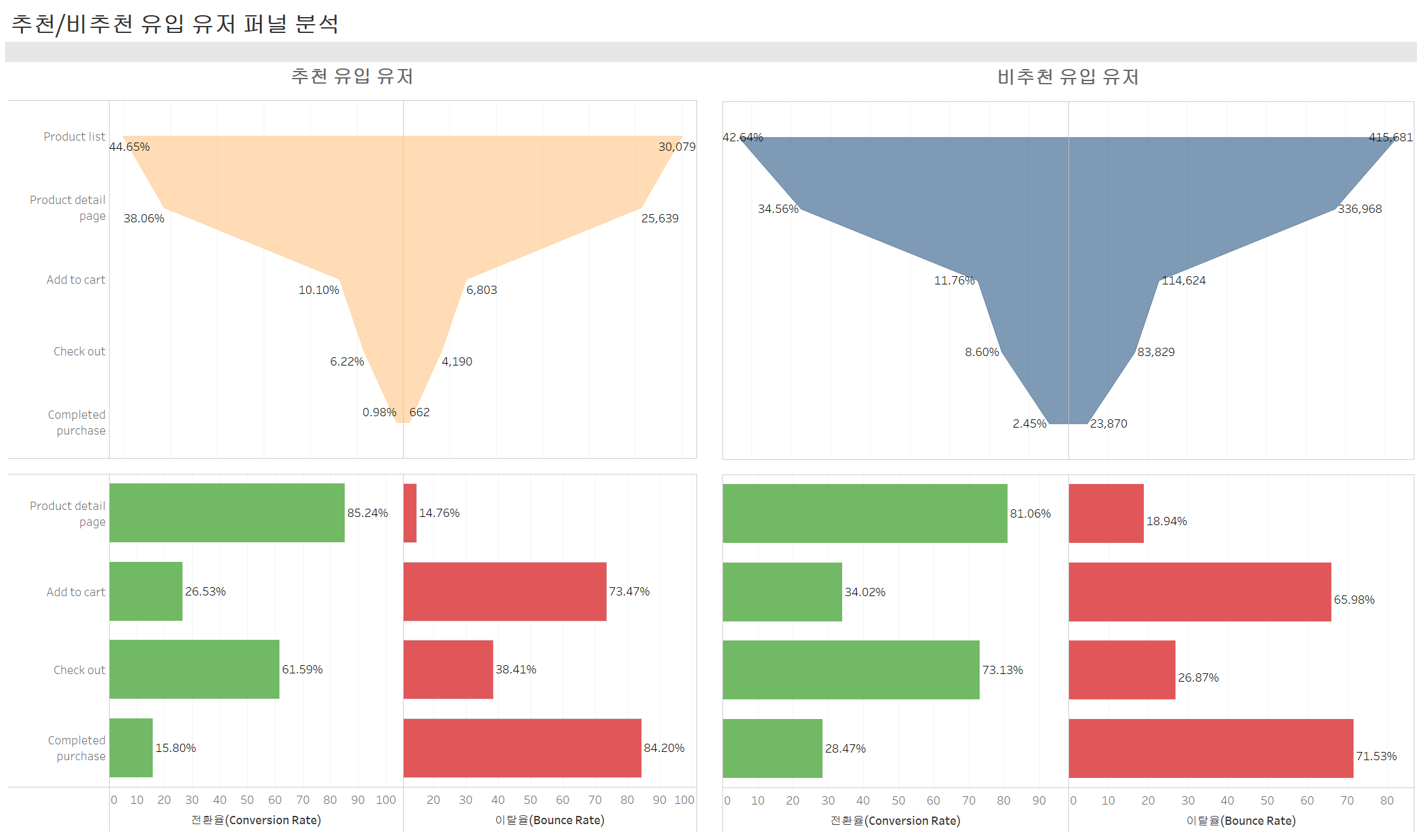
요약
추천으로 유입된 그룹이 그렇지 않은 그룹에 비해 평균 세션 지속 시간과 RPV가 높을 것으로 예상했지만,
측정해본 결과 오히려 추천으로 유입되지 않은 그룹의 수치가 근소하게 더 높았다.
그래서 이 결과가 통계적으로 유의미한지 알아보기 위해 t-검정을 시행했다.
하지만 결과는 p-value = 0.9531, 두 그룹간 수치의 평균 차이는 유의하지 않다고 할 수 있다는 결과를 얻었다.
이제 두 그룹의 퍼널별 전환율의 차이가 있는지 알아보기 위해 양비율 Z-검정(Two-Proportion Z-Test)를 퍼널별로 시행했는데, 다중 비교 문제를 방지하기 위해 본페로니 교정을 사용했다.
따라서 유의수준 5%를 퍼널 개수 4로 나눠서 나온 1.25%로 교정하고 테스트를 시행한 결과, 모든 퍼널에서 그룹간 전환율 차이가 유의하지 않다는 결과가 나왔다.
마지막 Refferal 단계를 끝으로 AARRR 프로젝트를 마칩니다.
참고 노트북
'Project' 카테고리의 다른 글
| [AARRR] #4. Revenue (수익) [RPV, RFM 분석, LTV] (0) | 2025.03.27 |
|---|---|
| [AARRR] #3. Retention (유지) [코호트 분석(Cohort Analysis), 다중회귀분석] (0) | 2025.03.17 |
| [AARRR] #2. Activation (활성화) [퍼널 분석(Funnel Analysis)] (0) | 2025.03.14 |
| [AARRR] #1. Acquisition(획득) [Google Analytics(GA)] (0) | 2025.03.10 |



