Google Analytics란?
Google Analytics는 구글에서 제공하는 웹 및 모바일 앱의 트래픽과 사용자 행동을 분석하는 대표적인 웹 분석 도구이다. 웹사이트나 앱에 제공되는 자바스크립트 트래킹 코드를 삽입하면, 방문자가 사이트에 접속할 때마다 그 행동(페이지 조회, 세션 지속 시간, 이탈률, 전환 등)을 자동으로 기록하고, 이 데이터를 기반으로 다양한 보고서를 생성한다.
BigQuery란?
빅쿼리(BigQuery)는 구글 클라우드 플랫폼에서 제공하는 서버리스 데이터 웨어하우스 서비스이다. 별도의 인프라 관리 없이, SQL을 통해 페타바이트(PB) 규모의 대용량 데이터를 빠르게 저장, 분석, 쿼리할 수 있도록 설계되어 있다.
AARRR 분석이란?
AARRR은 사용자의 서비스 이용흐름을 기반으로 고객 획/ 활성화/ 유지/ 수익/ 추천 이라는 5가지 카테고리를 정의하고 각 카테고리에서 핵심이 되는 지표를 발굴하고 이를 측정/ 개선하는 지표관리 방법론이다.
- Acquisition (획득):
고객이 어떻게 해당 서비스나 제품을 알게 되었는지, 즉 유입 경로(검색, 미디어, 광고 등)를 분석. - Activation (활성화):
첫 방문 후 고객이 긍정적인 경험을 했는지 평가. 예를 들어, 회원 가입, 첫 구매, 앱 내 첫 행동 등이 이에 해당 됨. - Retention (유지):
고객이 제품이나 서비스를 반복적으로 이용하는지를 측정. 즉, 초기 경험 후 얼마나 많은 고객이 돌아오는지를 분석. - Revenue (수익):
고객으로부터 얼마나 수익을 창출할 수 있는지를 파악. 구매, 구독, 광고 클릭 등의 수익 창출 지표를 포함. - Referral (추천):
기존 고객이 다른 사람에게 제품이나 서비스를 추천하는지, 즉 자연스러운 입소문 효과를 분석.
이번 포스팅에서는 AARRR의 네 번째 순서인 Revenue (수익) 단계에 대해 분석할 것이다.
Revenue (수익)
사용자가 우리 서비스에 대해 실제 비용을 지불하는가?
서비스의 핵심 가치를 금전적 가치로 전환시켜 수익을 창출하고, 그 수준을 측정할 수 있는 지표를 정의하고 관리하는 단계.
이번 단계에서 수행할 분석
- 그룹별 RPV(방문당 평균 수익) 비교 분석
- RFM 분석을 통한 고객 세그먼트 분류
- 고객 세그먼트별 ARPU(사용자당 평균 수익), RPR(재구매율), LTV(고객생애가치) 산출
그룹별 RPV 비교 분석
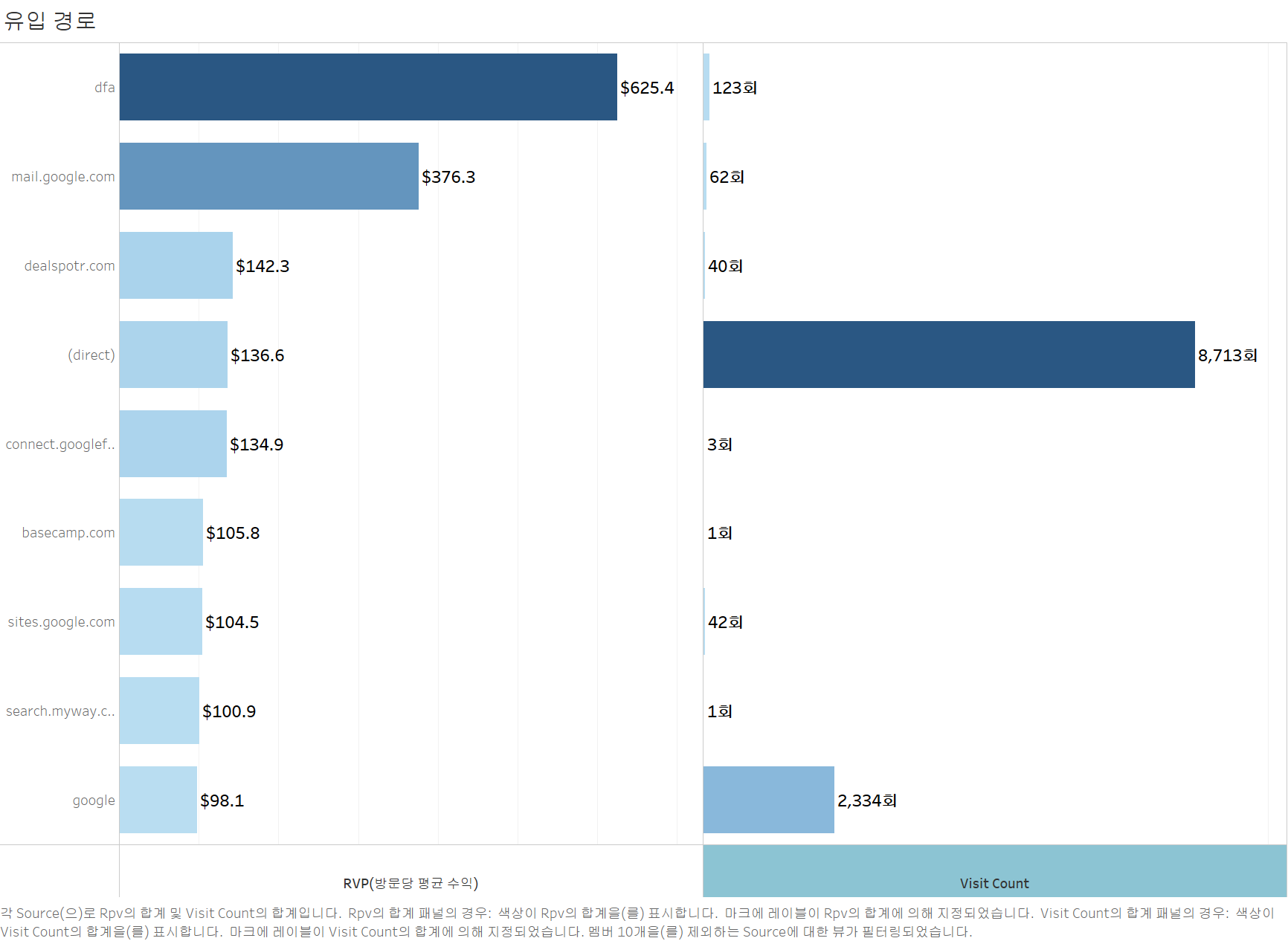
1. 유입 경로별 RPV
# 유입 경로별 방문당 평균 수익
query = f"""
SELECT
trafficSource.source AS source,
count(*) AS visit_count,
SUM(totals.transactionRevenue) / 1000000 AS total_revenue, -- 해당 변수는 마이크로 단위이므로 1,000,000으로 나눠야 함
SUM(totals.transactionRevenue) / 1000000 / COUNT(*) AS rpv -- 방문당 평균 수익(Revenue per Visit, RPV)
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170801'
AND totals.transactionRevenue > 0
GROUP BY
source
ORDER BY
rpv DESC
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_inflow_RPV = query_job.to_dataframe()
# 결과 출력
df_inflow_RPV
2. 캠페인별 RPV
# 캠페인별 세션 수 분석 쿼리 작성
query = """
SELECT
trafficSource.campaign AS campaign,
COUNT(*) AS visit_count,
SUM(totals.transactionRevenue) / 1000000 AS total_revenue, -- 해당 변수는 마이크로 단위이므로 1,000,000으로 나눠야 함
SUM(totals.transactionRevenue) / 1000000 / COUNT(*) AS rpv -- 방문당 평균 수익(Revenue per Visit, RPV)
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170801'
AND totals.transactionRevenue > 0
GROUP BY
campaign
ORDER BY
rpv DESC
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_campaign_RPV = query_job.to_dataframe()
# 결과 출력
df_campaign_RPV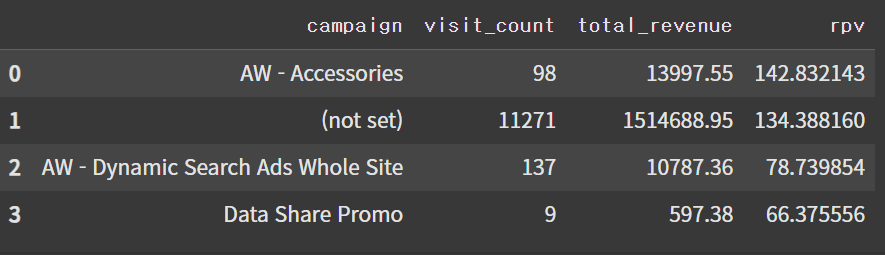
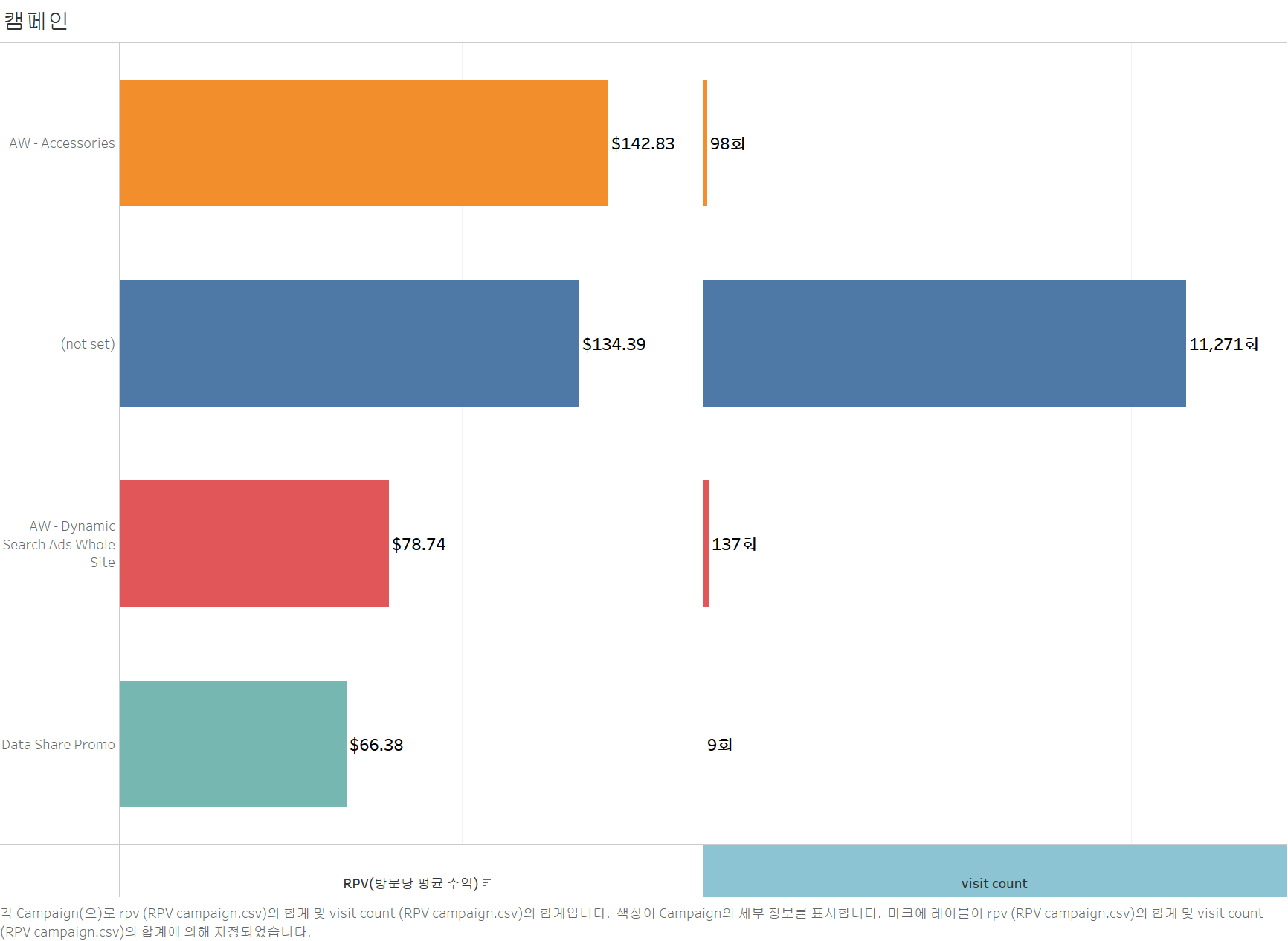
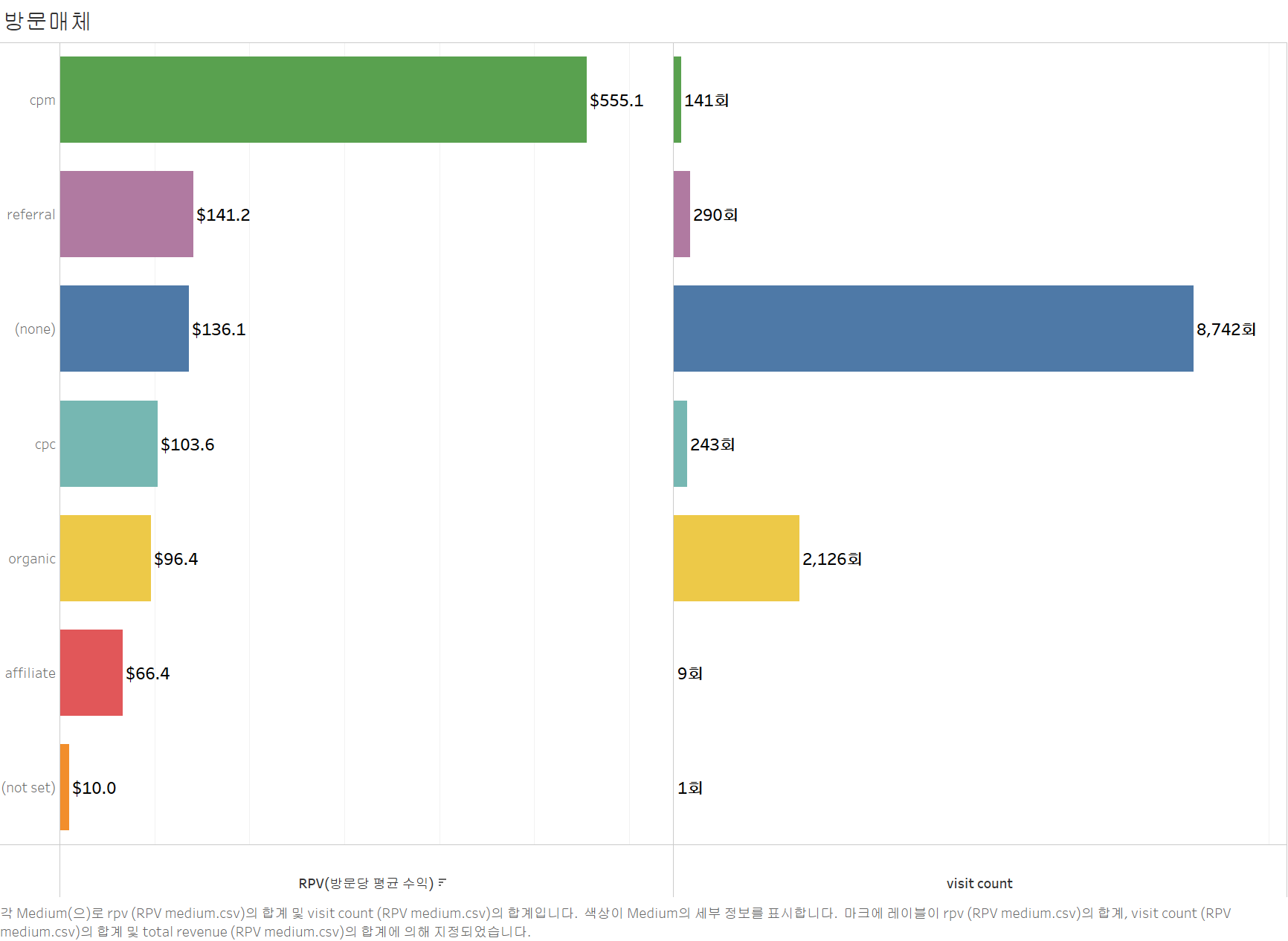
3. 방문 매체
# 방문 매체별 수익 분석 쿼리 작성
query = """
SELECT
trafficSource.medium AS medium,
COUNT(*) AS visit_count,
SUM(totals.transactionRevenue) / 1000000 AS total_revenue, -- 해당 변수는 마이크로 단위이므로 1,000,000으로 나눠야 함
SUM(totals.transactionRevenue) / 1000000 / COUNT(*) AS rpv -- 방문당 평균 수익(Revenue per Visit, RPV)
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170801'
AND totals.transactions > 0
GROUP BY
medium
ORDER BY
rpv DESC
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_medium = query_job.to_dataframe()
# 결과 출력
df_medium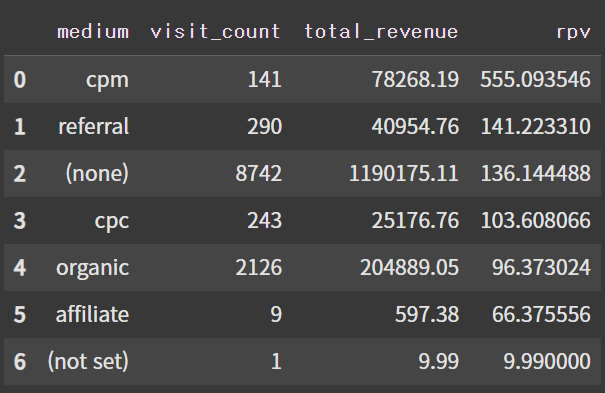
RFM 분석
RFM 분석
고객의 구매 행동을 기반으로 충성도 높은 고객을 식별하고 마케팅 전략을 최적화하는 데 사용되는 데이터 분석 기법.
RFM 분석의 세 가지 요소
- Recency (최신성): 현재날짜와 고객이 마지막으로 구매한 날짜의 차이
- Frequency (빈도): 고객이 특정 기간 동안 몇 번 구매했는지 (구매 횟수)
- Monetary (금액): 고객이 특정 기간 동안 총 얼마를 소비했는지 (구매 금액)
1. R, F, M 변수 생성
# RFM 변수 생성 쿼리 작성
query = f"""
SELECT
fullVisitorId,
DATE_DIFF(
PARSE_DATE('%Y%m%d', '20170802'),
MAX(PARSE_DATE('%Y%m%d', TRIM(_TABLE_SUFFIX))), -- 앞뒤에 공백이 포함된 문자형이 있는 것으로 추정. TRIM 사용
DAY
) AS recency,
COUNT(*) AS frequency,
SUM(totals.transactionRevenue) / 1000000 AS monetary -- 마이크로 단위이므로 변환
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
TRIM(_TABLE_SUFFIX) BETWEEN '20160801' AND '20170801'
AND totals.transactions > 0
GROUP BY
fullVisitorId
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_rfm = query_job.to_dataframe()
# 결과 출력
df_rfm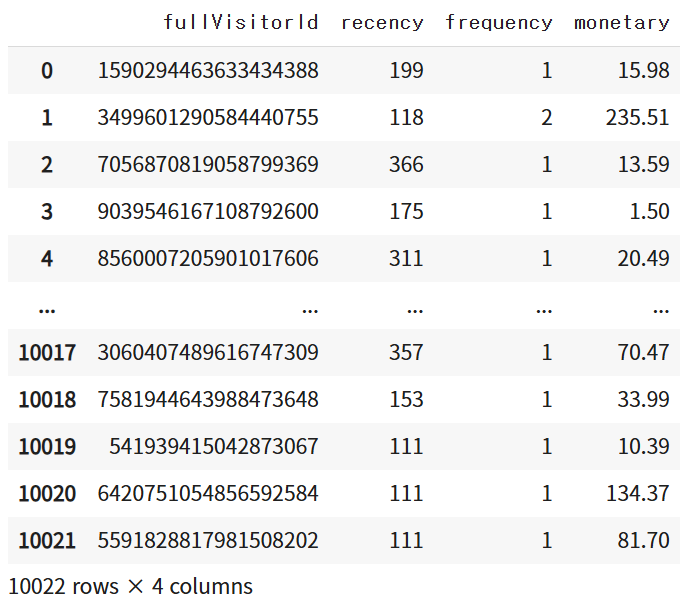
2. R, F, M 점수 설정
- Recency (최근성) 점수: 최근 방문한 고객이 높은 점수(5)
- Frequency (빈도) 점수: 자주 방문한 고객이 높은 점수(1 or 2이상)
- Monetary (구매 금액) 점수: 많이 구매한 고객이 높은 점수(5)
# R 값의 경우 수치가 커질수록 낮은 점수 부여 (수치가 크면 구매한 지 오래 됐다는 의미)
r_labels = list(range(5, 0, -1)) # Recency (최근성) 점수: 최근 방문한 고객이 높은 점수(5)
m_labels = list(range(1,6)) # Monetary (구매 금액) 점수: 많이 구매한 고객이 높은 점수(5)
interval = 5
# r_cut: rfm_df['recency']를 같은 크기로 interval 개의 구간으로 나누는데 구간별 이름은 r_labels로 한다.
r_cut = pd.qcut(df_rfm['recency'], interval, labels = r_labels)
m_cut = pd.qcut(df_rfm['monetary'], interval, labels = m_labels)
# rfm_df에 각각의 점수 할당
rfm_df = df_rfm.assign(R_score = r_cut,
F_score = np.where(df_rfm['frequency'] >= 2, 2, 1),
M_score = m_cut)
# monetary에 26개의 결측치 존재 -> 제거
rfm_df = rfm_df.dropna()
rfm_df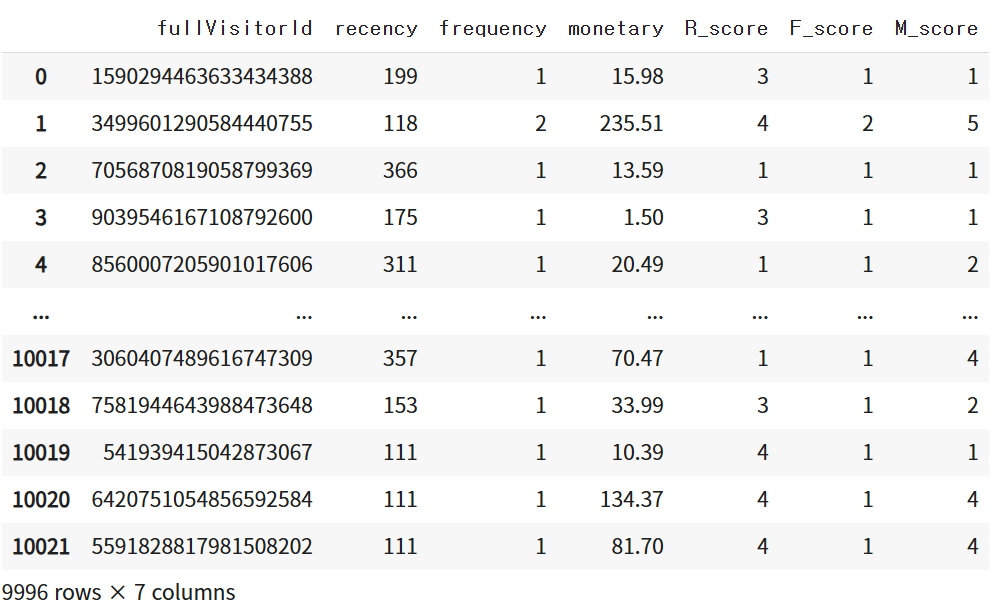
3. 고객 세분화
def classify_customer_segment(row):
R, F, M = row['R_score'], row['F_score'], row['M_score']
if R == 5 and F == 2 and M == 5:
return 'Champions'
elif R >= 3 and F >= 1 and M >= 4:
return 'Loyal Customers'
elif R >= 2 and F >= 1 and M >= 1:
return 'At Risk'
elif R == 1 and F >= 1 and M >= 1:
return 'Lost'
rfm_df['Segment'] = rfm_df.apply(classify_customer_segment, axis=1)
rfm_df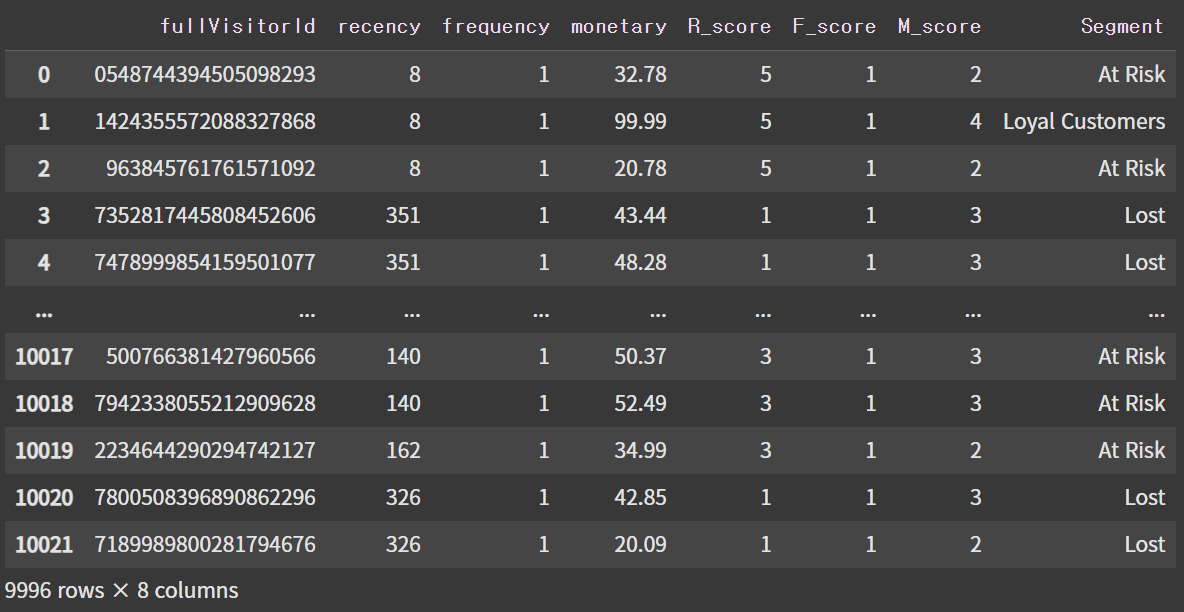
# 각 세그먼트의 비율
rfm_df['Segment'].value_counts(normalize=True)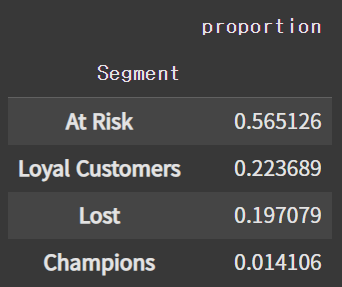
4. 각 세그먼트별 ARPU, RPR, LTV 분석
- 사용자당 평균 수익 (ARPU, Average Revenue Per User) = 총 매출액 / 총 고객 수
- 재구매율 (RPR, Repeat Purchase Rate) = 구매 고객 수 / 두 번 이상 구매한 고객 수
- 고객 생애 가치 (LTV, Customer Lifetime Value) = ARPU * 고객 평균 생애 기간 (고객이 평생 창출할 수 있는 총 가치를 추정)
이 때, 고객 평균 생애 기간은 고객별로 첫 구매일과 마지막 구매일의 날짜 차이를 계산한 후 세그먼트별로 평균을 낸 값으로 정의.
# duckdb는 ga_sessions_와 같은 와일드카드 테이블을 참조할 수 없으므로 해당 테이블을 대체할 임시 데이터프레임 생성
query = f"""
SELECT
fullVisitorId,
DATE_DIFF(
MAX(PARSE_DATE('%Y%m%d', TRIM(_TABLE_SUFFIX))),
MIN(PARSE_DATE('%Y%m%d', TRIM(_TABLE_SUFFIX))),
DAY
) AS date_diff
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
TRIM(_TABLE_SUFFIX) BETWEEN '20160801' AND '20170801'
AND totals.transactions > 0
GROUP BY
fullVisitorId
ORDER BY
fullVisitorId
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_datediff = query_job.to_dataframe()
df_datediff['date_diff'] = df_datediff['date_diff'] + np.repeat(1, 10022)# 고객 세그먼트별 ARPU, 재구매율, LTV 계산 쿼리 작성
import duckdb
query = f"""
WITH
RE AS ( -- 2번 이상 구매한 고객 수의 세그먼트별 합계
SELECT
Segment,
COUNT(*) AS count_over_twice
FROM
rfm_df
WHERE
F_score > 1
GROUP BY
Segment
)
SELECT
rfm.Segment,
-- 세그먼트 내 고객당 평균 구매금액 (ARPU)
SUM(rfm.monetary) / COUNT(df.fullVisitorId) AS ARPU,
-- 재구매율: (2번 이상 구매한 고객 수) / (해당 세그먼트의 고객 수)
RE.count_over_twice / COUNT(df.fullVisitorId) AS RPR,
-- LTV: ARPU * 평균 고객 생애기간(일)
(SUM(rfm.monetary) / COUNT(df.fullVisitorId)) * AVG(df.date_diff) AS LTV
FROM
rfm_df AS rfm
JOIN df_datediff AS df USING (fullVisitorId)
LEFT JOIN RE ON rfm.Segment = RE.Segment
GROUP BY
rfm.Segment,
RE.count_over_twice
"""
df_segment = duckdb.query(query).to_df()
# One-Time Customers은 재구매한 고객이 없으므로 결측치가 할당되는데, 이것을 0으로 대체한다.
df_segment = df_segment.fillna(0)
df_segment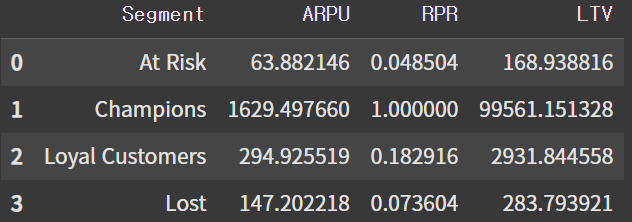
5. 시각화

인사이트
1. 세그먼트별 고객 분포
- At Risk 그룹이 가장 큰 비중(56.5%)을 차지하고 있다.
- 이들을 어떻게 재활성화하고 유지할지에 대한 전략 필요
- Loyal Customers(22.4%), Lost(19.7%), Champions(1.4%) 순으로 분포
- 또한, Lost 그룹도 적지 않은 비율을 차지하고 있어 왜 이탈했는지 파악하는 작업이 중요
- 해당 작업은 퍼널 분석(Funnel Analysis)으로 보다 자세히 파악 가능(본 블로그의 [AARRR #2. Activation] 게시글 참고).
2. 세그먼트별 특징
- Champions
- 높은 구매빈도, 재구매율, 구매금액을 보유한 핵심 고객 그룹
- ARPU, RPR, LTV 모두 높으므로 이탈 방지 및 VIP 혜택을 통한 만족도 유지가 중요.
- Loyal Customers
- 중간 이상의 구매빈도, 재구매율, 구매금액을 유지
- Champions 등급으로 성장할 가능성이 크므로 리텐션 강화 전략 필요
- At Risk
- 가장 큰 비중이지만 매출 기여도는 낮은 편
- 이탈 방지를 위해 리마인드 알림, 쿠폰 제공 등의 혜택이 필요
- 어떤 패턴의 고객이 이탈하는지 파악해서 이탈을 최소화 시키는 것이 중요
- Lost
- 이미 이탈했지만 At Risk 그룹보다 높은 지표들을 보유하고 있어, 복귀 시 상당한 수익을 기대할 수 있음.
- 이탈 사유(가격 경쟁, 경쟁사 프로모션, UX 문제 등)를 파악하고, 이를 해결할 수 있는 Win-Back 전략 마련.
3. 결론
Champions, Loyal Customers 등급의 고객에게는 VIP 혜택 제공, 업셀링 전략으로 장기적 관계를 구축하고 매출을 더욱 높이고, At Risk, Lost 등급의 고객에게는 프로모션, 재활성화 캠페인을 통해 이탈 방지 및 복귀를 유도해서 전반적인 매출 상승을 기대할 수 있을 것이다.
참조 노트북



