Google Analytics란?
Google Analytics는 구글에서 제공하는 웹 및 모바일 앱의 트래픽과 사용자 행동을 분석하는 대표적인 웹 분석 도구이다. 웹사이트나 앱에 제공되는 자바스크립트 트래킹 코드를 삽입하면, 방문자가 사이트에 접속할 때마다 그 행동(페이지 조회, 세션 지속 시간, 이탈률, 전환 등)을 자동으로 기록하고, 이 데이터를 기반으로 다양한 보고서를 생성한다.
BigQuery란?
빅쿼리(BigQuery)는 구글 클라우드 플랫폼에서 제공하는 서버리스 데이터 웨어하우스 서비스이다. 별도의 인프라 관리 없이, SQL을 통해 페타바이트(PB) 규모의 대용량 데이터를 빠르게 저장, 분석, 쿼리할 수 있도록 설계되어 있다.
AARRR 분석이란?
AARRR은 사용자의 서비스 이용흐름을 기반으로 고객 획/ 활성화/ 유지/ 수익/ 추천 이라는 5가지 카테고리를 정의하고 각 카테고리에서 핵심이 되는 지표를 발굴하고 이를 측정/ 개선하는 지표관리 방법론이다.
- Acquisition (획득):
고객이 어떻게 해당 서비스나 제품을 알게 되었는지, 즉 유입 경로(검색, 미디어, 광고 등)를 분석. - Activation (활성화):
첫 방문 후 고객이 긍정적인 경험을 했는지 평가. 예를 들어, 회원 가입, 첫 구매, 앱 내 첫 행동 등이 이에 해당 됨. - Retention (유지):
고객이 제품이나 서비스를 반복적으로 이용하는지를 측정. 즉, 초기 경험 후 얼마나 많은 고객이 돌아오는지를 분석. - Revenue (수익):
고객으로부터 얼마나 수익을 창출할 수 있는지를 파악. 구매, 구독, 광고 클릭 등의 수익 창출 지표를 포함. - Referral (추천):
기존 고객이 다른 사람에게 제품이나 서비스를 추천하는지, 즉 자연스러운 입소문 효과를 분석.
이번 포스팅에서는 AARRR의 세 번째 순서인 Retention (유지) 단계에 대해 분석할 것이다.
Retention (유지)
사용자가 우리 서비스에 지속적으로 방문하는가?
Active 과정을 통해 경험한 핵심가치를 꾸준히 경험하게 하고, 그 수준을 측정할 수 있는 지표를 정의하고 관리하는 단계.
Retention단계의 핵심은 코호트 분석(Cohort Analysis).
- 특정 기간이나 기준에 따라 사용자 집단(코호트)을 나누어, 이들이 시간에 따라 어떻게 행동하는지 분석하는 기법
- 단순한 전체 평균 지표만으로는 파악하기 어려운 사용자 행동의 세부 패턴을 드러낸다.
- 각 그룹의 재방문율을 분석함으로써 Retention 단계에서의 문제점을 도출하고 개선할 수 있다.
코호트 분석(Cohort Analysis)
GA 데이터에서 최초 유입 시점을 기준으로 사용자를 그룹화한 뒤, 일정 기간 동안 얼마만큼의 사용자가 재방문하는지를 추적하고, 채널별 코호트 비교를 통해 어떤 유입 경로가 장기적으로 더 효과적인지 분석할 것이다.
1. 목표 변수 생성
- month_started: 첫 구매월
- month_passed: 사용자별 첫 구매월부터 데이터의 마지막 날짜인 2017년 7월까지의 차이
- customer_count: 각 조건에 해당하는 고객의 수
# 첫 구매 월과 마지막 구매 월의 차이 기준으로 고객 카운팅 쿼리 작성
query = f"""
WITH purchase_sessions AS (
SELECT
fullVisitorId,
PARSE_DATE('%Y%m', SUBSTR(_TABLE_SUFFIX, 1, 6)) AS session_month
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170731'
AND totals.transactions > 0 -- 실제 구매 발생한 세션만 고려
),
first_last_purchase AS (
SELECT
fullVisitorId,
MIN(session_month) AS first_purchase_month,
MAX(session_month) AS last_purchase_month,
DATE_DIFF(MAX(session_month), MIN(session_month), MONTH) AS month_passed
FROM
purchase_sessions
WHERE
session_month IS NOT NULL
GROUP BY
fullVisitorId
)
SELECT
FORMAT_DATE('%Y-%m', first_purchase_month) AS month_started,
month_passed,
COUNT(DISTINCT fullVisitorId) AS customer_count
FROM
first_last_purchase
GROUP BY
month_started, month_passed
ORDER BY
month_started, month_passed
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_cohort = query_job.to_dataframe()
# 결과 출력
df_cohort
2. 피벗 테이블 생성
pivot_df = df_cohort.pivot(index='month_started', columns='month_passed')
pivot_df
3. 비율로 변환
customer_cohort = pivot_df.div(pivot_df.iloc[:, 0], axis=0)*100
customer_cohort = customer_cohort.round(decimals=2)
customer_cohort = customer_cohort.loc[:"2017-06", ("customer_count", slice(1, None))]
customer_cohort
- GA의 1년치 데이터 특성상 리텐션율이 다소 낮다.
- 위 숫자들과 month_passed = 0 칼럼에 할당된 100을 비교하면, 숫자의 현저한 차이 때문에 month_passed 칼럼끼리 명확히 비교하기 어려워진다.
- 따라서 month_passed = 0 칼럼은 시각화 단계에서의 가시성을 위해 제거했다.
4. 히트맵으로 시각화

여기서, 2016년 12월 코호트의 한 달차 리텐션율은 1.70%로 다른 코호트 대비 낮은 것을 확인할 수 있는데, 그 원인이 무엇일지 추측해보려 한다.
먼저, 각 유입 경로, 방문 매체, 캠페인 별로 재방문율을 측정한다.
그 다음 2016년 12월 코호트의 유입 경로나 방문 매체 등 각 집단의 세션 수를 측정하여 다른 코호트와의 차이점을 확인할 것이다.
1. 유입 경로, 방문 매체, 캠페인별 재방문율
(1) 유입 경로
# 유입경로별 재방문율 확인 쿼리 작성
query = f"""
WITH user_sessions AS (
SELECT
fullVisitorId,
MIN(PARSE_DATE('%Y%m%d', _TABLE_SUFFIX)) AS first_date,
ANY_VALUE(trafficSource.source) AS source,
COUNT(*) AS session_count
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170731'
GROUP BY
fullVisitorId
)
SELECT
source,
COUNT(*) AS total_users,
COUNTIF(session_count > 1) AS retained_users,
ROUND(COUNTIF(session_count > 1) / COUNT(*), 2) AS retention_rate
FROM
user_sessions
GROUP BY
source
ORDER BY
total_users DESC,
retention_rate DESC
LIMIT 50
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_rtn_inf = query_job.to_dataframe()
# 결과 출력
df_rtn_inf
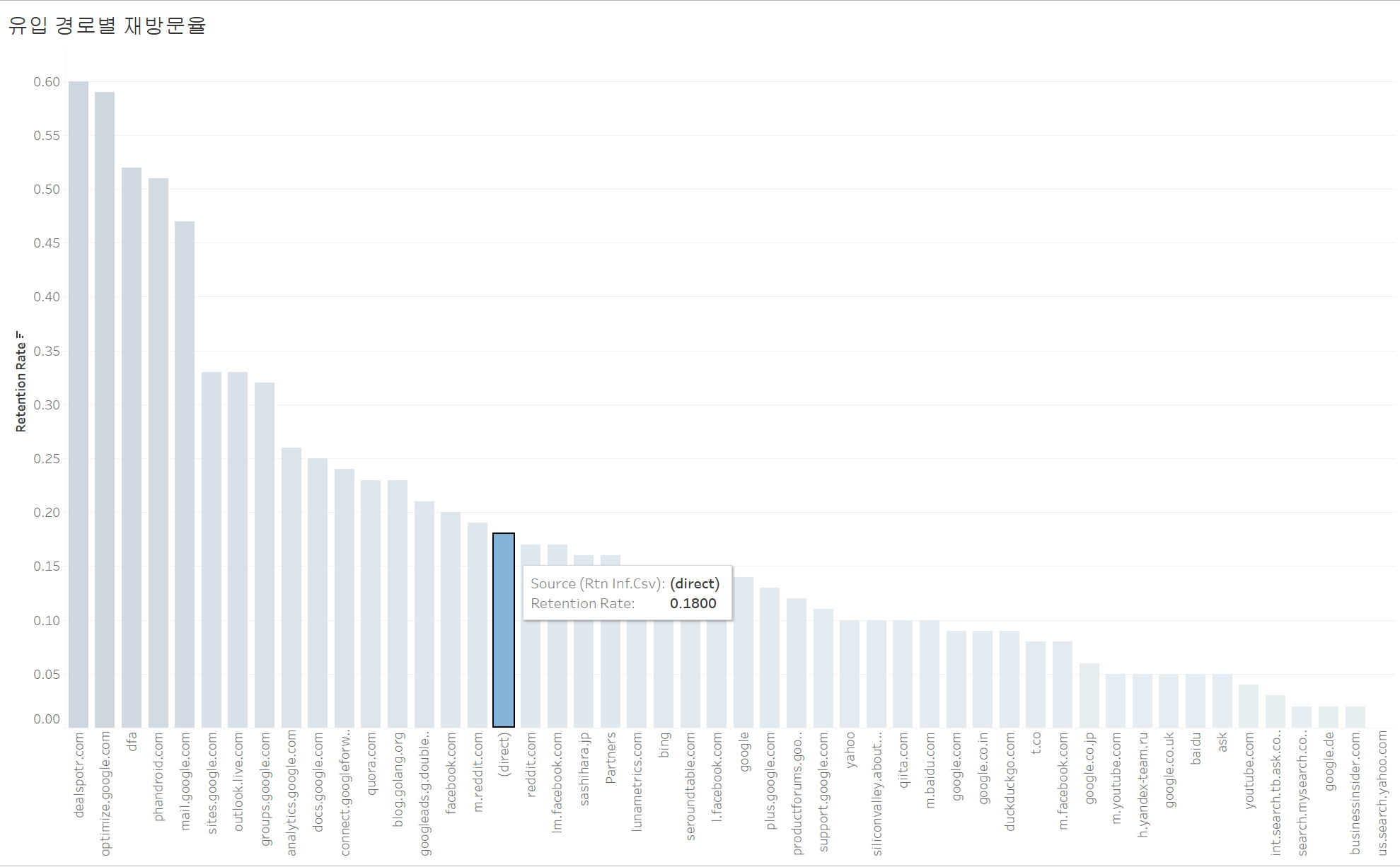
유입 경로별 재방문율은 위 그래프와 같고, 가장 높은 세션 수를 보유한 (direct)의 재방문율은 약 18%로 다른 유입 경로와 비교했을 때, 중간 수준의 재방문율을 보인다.
(2) 방문 매체
# 방문매체별 재방문율 확인 쿼리 작성
query = f"""
WITH user_sessions AS (
SELECT
fullVisitorId,
MIN(PARSE_DATE('%Y%m%d', _TABLE_SUFFIX)) AS first_date,
ANY_VALUE(trafficSource.medium) AS medium,
COUNT(*) AS session_count
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170731'
GROUP BY
fullVisitorId
)
SELECT
medium,
COUNT(*) AS total_users,
COUNTIF(session_count > 1) AS retained_users,
ROUND(COUNTIF(session_count > 1) / COUNT(*), 2) AS retention_rate
FROM
user_sessions
GROUP BY
medium
ORDER BY
total_users DESC,
retention_rate DESC
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_rtn_med = query_job.to_dataframe()
# 결과 출력
df_rtn_med

가장 높은 세션을 보유한 (none)은 약 18%로 다른 방문 매체에 비해 상대적으로 낮은 재방문율을 보인다.
(3) 캠페인
# 캠페인별 재방문율 확인 쿼리 작성
query = f"""
WITH user_sessions AS (
SELECT
fullVisitorId,
MIN(PARSE_DATE('%Y%m%d', _TABLE_SUFFIX)) AS first_date,
ANY_VALUE(trafficSource.campaign) AS campaign,
COUNT(*) AS session_count
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170731'
GROUP BY
fullVisitorId
)
SELECT
campaign,
COUNT(*) AS total_users,
COUNTIF(session_count > 1) AS retained_users,
ROUND(COUNTIF(session_count > 1) / COUNT(*), 2) AS retention_rate
FROM
user_sessions
GROUP BY
campaign
ORDER BY
total_users DESC,
retention_rate DESC
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_rtn_cpn = query_job.to_dataframe()
# 결과 출력
df_rtn_cpn

(not set)의 경우 약 13%로 다른 캠페인에 비해 낮은 재방문율을 보인다.
2. 월별 유입 경로, 방문 매체, 캠페인 확인
(1) 유입 경로
# 월별 유입경로 변화 확인 쿼리 작성
query = f"""
SELECT
FORMAT_DATE('%Y-%m', PARSE_DATE('%Y%m', SUBSTR(_TABLE_SUFFIX, 1, 6))) AS date,
trafficSource.source AS source,
COUNT(*) AS visit_count
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170731'
AND totals.transactionRevenue > 0
GROUP BY
date,
trafficSource.source
ORDER BY
date,
visit_count DESC
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_inf = query_job.to_dataframe()
# 결과 출력
df_inf


위 그래프에서, 2016년 12월은 재방문율이 중간 수준인 (direct)의 세션 수가 다른 달에 비해 매우 높은 것을 확인할 수 있다.
(2) 방문 매체
# 월별 방문매체 변화 확인 쿼리 작성
query = f"""
SELECT
FORMAT_DATE('%Y-%m', PARSE_DATE('%Y%m', SUBSTR(_TABLE_SUFFIX, 1, 6))) AS date,
trafficSource.medium AS medium,
COUNT(*) AS visit_count
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170731'
AND totals.transactionRevenue > 0
GROUP BY
date,
medium
ORDER BY
date,
visit_count DESC
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_med = query_job.to_dataframe()
# 결과 출력
df_med
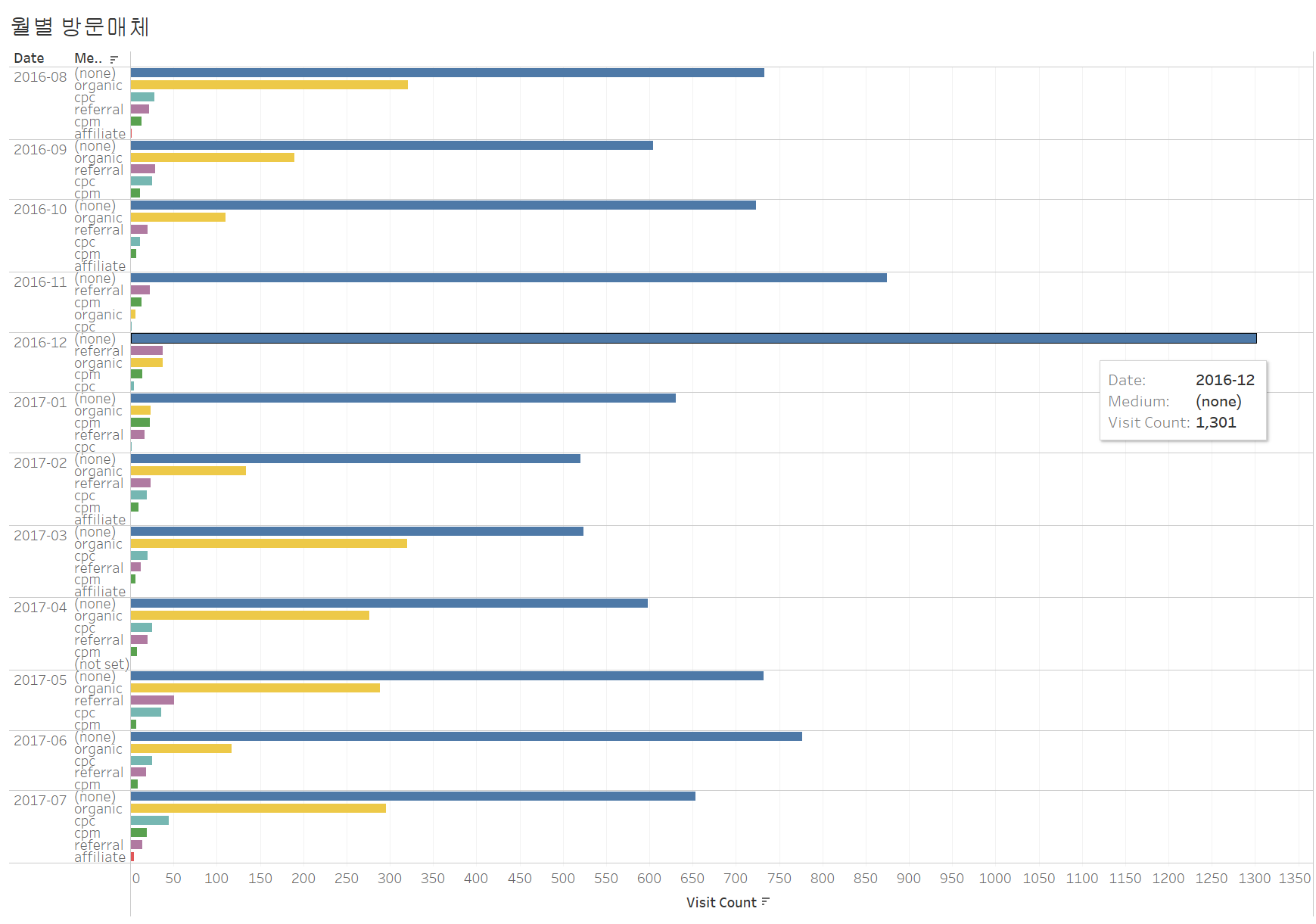
위의 그래프 역시 2016년 12월에 재방문율이 낮은 수준인 (none)의 세션 수가 다른 달에 비해 높은 것을 확인할 수 있다.
(3) 캠페인
# 월별 캠페인 변화 확인 쿼리 작성
query = f"""
SELECT
FORMAT_DATE('%Y-%m', PARSE_DATE('%Y%m', SUBSTR(_TABLE_SUFFIX, 1, 6))) AS date,
trafficSource.campaign AS campaign,
COUNT(*) AS visit_count
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170731'
AND totals.transactionRevenue > 0
GROUP BY
date,
campaign
ORDER BY
date,
visit_count DESC
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_cpn = query_job.to_dataframe()
# 결과 출력
df_cpn
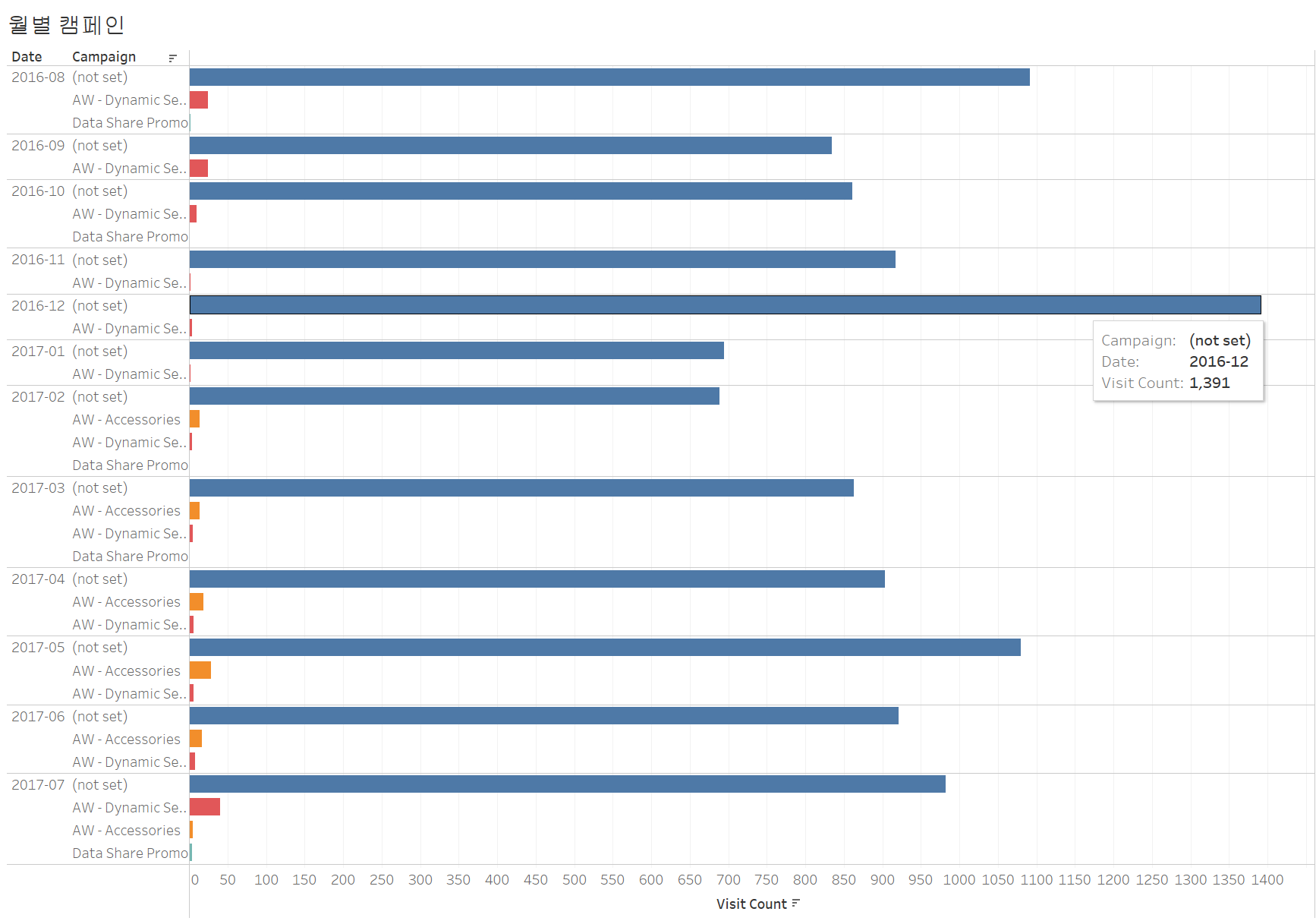
이번 그래프 역시 2016년 12월에 재방문율이 낮은 수준인 (not set)의 세션 수가 다른 달보다 높으며, 재방문율이 높은 수준인 AW - Dynamic Search Ads Whole Site, AW - Accessories 두 캠페인의 세션 수가 매우 낮거나 없다는 것을 확인할 수 있다.
3. 가설검정
위 결과를 바탕으로 "세션이 (direct), (none), (not set) 를 통해 유입된 것이면 리텐션율은 낮아진다." 라는 가설을 세우고 R을 이용해 다중회귀분석으로 검정해보겠다.
(1) 데이터 전처리
먼저 분석에 사용될 변수들을 로드하고 회귀모형 적합에 필요한 형태로 전처리하는 과정이 필요하다.
사용할 변수:
- retention_rate = 리텐션율 (종속변수)
- date_dummy = 2016년 12월 코호트이면 1, 아니면 0
- source_dummy = 유입경로가 (direct)이면 1, 아니면 0
- medium_dummy = 방문매체가 (none)이면 1, 아니면 0
- campaign_dummy = 캠페인이 (not set)이면 1, 아니면 0
- 위 변수들의 교호작용 변수들
먼저 월, id, 유입경로, 방문매체, 캠페인 변수를 포함한 테이블을 생성한다.
# 월, id, 유입경로, 방문매체, 캠페인 포함 테이블 생성 쿼리 작성
query = f"""
SELECT
FORMAT_DATE('%Y-%m', PARSE_DATE('%Y%m', SUBSTR(_TABLE_SUFFIX, 1, 6))) AS date,
fullVisitorId AS id,
trafficSource.source AS source,
trafficSource.medium AS medium,
trafficSource.campaign AS campaign
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170731'
GROUP BY
date, id, source, medium, campaign
ORDER BY
date,
fullVisitorId
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df = query_job.to_dataframe()
# 결과 출력
df
생성한 테이블을 csv파일로 저장한 후, R에서 로드한다.
# Cohort 데이터 로드 (리텐션율 포함)
cohort = read.csv('customer_cohort.csv')
cohort = cohort[cohort$month_passed == 1, -2]
colnames(cohort) = c('month', 'retention_rate')
cohort
df = read.csv('dataframe.csv')
head(df)
str(df)
데이터를 로드한 다음, 회귀모형에 필요한 더미변수를 생성하고 cohort 데이터와 월 기준으로 병합한다.
# 더미변수 생성
df$date_dummy = ifelse(df$date == '2016-12', 1, 0)
df$source_dummy = ifelse(df$source == '(direct)', 1, 0)
df$medium_dummy = ifelse(df$medium == '(none)', 1, 0)
df$campaign_dummy = ifelse(df$campaign == '(not set)', 1, 0)
# date 형식 맞추기
cohort$month = c('2016-08',
'2016-09',
'2016-10',
'2016-11',
'2016-12',
'2017-01',
'2017-02',
'2017-03',
'2017-04',
'2017-05',
'2017-06')
# 병합
colnames(df)[1] = 'month'
df = merge(df, cohort, by = 'month')
df
이제 회귀분석에 필요한 변수들이 준비되었으니, 다중회귀모형을 적합해보겠다.
(2) 다중회귀분석 (Multiple Linear Regression)
다중회귀분석은 두 개 이상의 독립 변수(X)와 하나의 종속 변수(Y) 간의 관계를 분석하는 통계 기법이다. 선형 회귀의 확장된 형태로, 여러 개의 설명 변수를 사용하여 종속 변수를 더 정확하게 예측하거나 설명할 수 있다.
이제 회귀모형을 적합해서 변수들의 회귀계수와 p-value를 확인하고 유의한지 판단해 보겠다.
먼저
- date_dummy: 코호트가 2016년 12월이면 1, 아니면 0
- source_dummy: 유입경로가 (direct)이면 1, 아니면 0
- medium_dummy: 방문매체가 (none)이면 1, 아니면 0
- campaign_dummy: 캠페인이 (not set)이면 1, 아니면 0
- date_dummy와 source_dummy의 교호작용
- date_dummy와 medium_dummy의 교호작용
- date_dummy와 campaign_dummy의 교호작용
을 포함한 모델이다
# 모형 적합
fit = lm(retention_rate ~
date_dummy +
date_dummy*source_dummy +
date_dummy*medium_dummy +
date_dummy*campaign_dummy,
data = df)
summary(fit)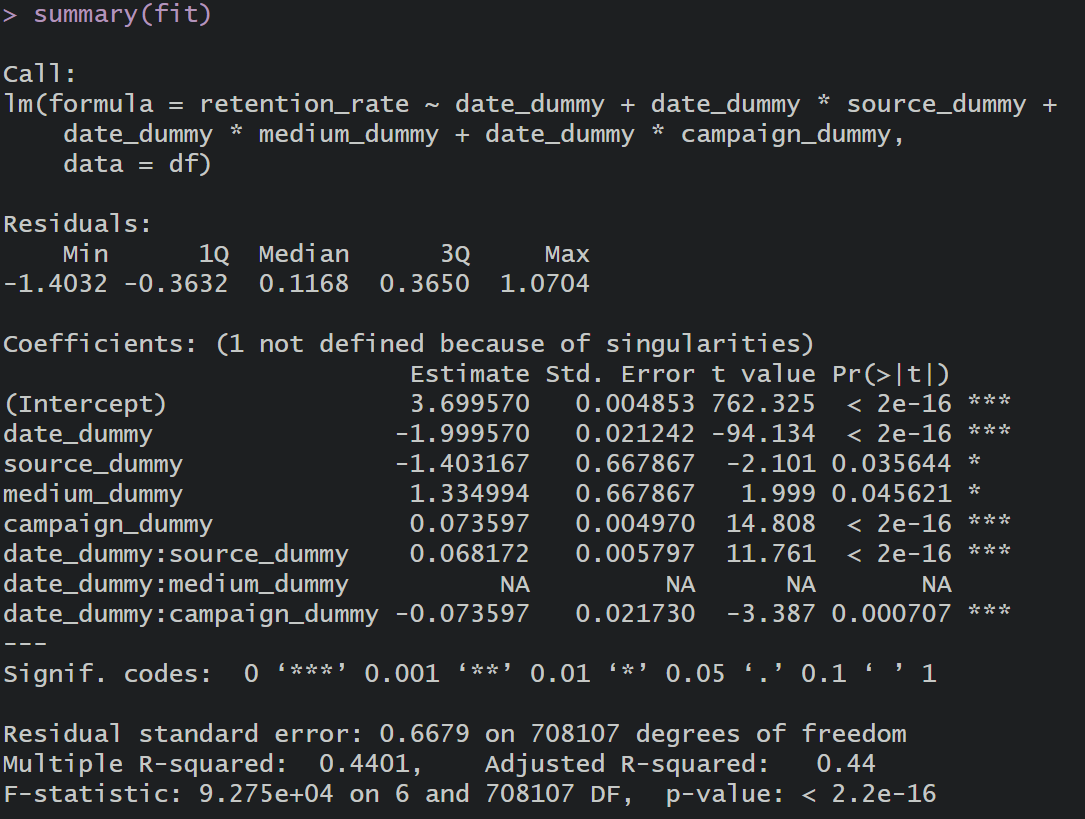
모형 적합 결과 가장 먼저 눈에 띄는 것은 date_dummy와 medium_dummy의 교호작용 항이 NA값이 출력된 것이다.
이는 모델에 포함된 변수들 간에 완벽한 다중공선성(또는 선형 종속성이) 존재하여, R이 해당 계수를 추정할 수 없었기 때문이다.
그렇다면 이제 alias() 함수를 사용해 해당 교호작용 항이 어떤 변수와 종속성이 존재하는지 알아보자.
alias(lm(retention_rate ~
date_dummy +
date_dummy*source_dummy +
date_dummy*medium_dummy +
date_dummy*campaign_dummy,
data = df))
위의 결과로 date_dummy와 source_dummy의 교호작용 항이 date_dummy와 medium_dummy의 교호작용 항과 완전한 종속 상태에 있다는 것을 알 수 있다.
이제, 종속성이 있는 변수를 하나로 줄이고 다시 모형을 적합해보자.
fit1 = lm(retention_rate ~
date_dummy +
date_dummy*source_dummy +
medium_dummy +
date_dummy*campaign_dummy,
data = df)
summary(fit1)
변수들의 p-value를 보니 모든 항이 유의수준 0.05보다 작으므로 더이상 변수를 수정할 필요가 없다고 판단된다.
적합한 회귀모형을 해석해 보자면
- 모든 변수의 유의확률이 0.05 미만이므로 모든 항이 유의하다.
- 모든 더미변수가 0일때, 리텐션율은 약 3.70이다.
- date_dummy가 0인 상태에서, source_dummy가 0에서 1로 바뀔 때 retention_rate가 평균적으로 약 1.40 감소한다.
- medium_dummy가 0에서 1로 바뀔 때, 다른 변수들이 동일한 조건 하에서 retention_rate가 평균적으로 약 1.33 증가한다.
- date_dummy가 0인 상태에서, campaign_dummy가 0에서 1로 바뀔 때 retention_rate가 평균적으로 약 0.074 증가한다.
- source_dummy, date_dummy 모두 1일 때, retention_rate가 평균적으로 약 0.068 증가한다.
- campaign_dummy, date_dummy 모두 1일 때, retention_rate가 평균적으로 약 0.074 감소해서 campaign_dummy 변수의 효과가 0으로 상쇄된다.
- 결정계수가 약 0.44로 위의 변수들이 전체 변동의 약 44%를 설명한다.
- 나머지 56%의 변동은 모델에 포함되지 않은 다른 요인들(오차, GA 데이터의 다른 변수 등)에 의해 설명된다고 할 수 있다.
인사이트
다중회귀분석을 이용해 각 변수들이 리텐션율에 미치는 영향을 분석해본 결과, 리텐션율은 코호트가 2016년 12월일 때와 유입경로가 (direct)일 때 감소하고, 방문매체가 (none)일 때 증가하며, campaign이 (not set)일 경우엔 큰 변화가 없는 것으로 나타났고, 그 외 교호작용 항들도 작지만 유의하다는 사실을 알 수 있었다.
하지만 결정계수가 약 0.44로 회귀모형이 데이터의 대부분의 변동을 설명한다고 보기에는 어렵기 때문에, 모형에 포함된 변수들 외에도 GA 데이터에 포함된 다른 요인들과 그 외 외부적 요인(연말 or 크리스마스 세일로 인한 단기 고객 유입 등)도 리텐션율에 적지 않은 영향을 미친다고 할 수 있다는 것이 이번 분석의 결론이다.
참조 노트북



