Google Analytics란?
Google Analytics는 구글에서 제공하는 웹 및 모바일 앱의 트래픽과 사용자 행동을 분석하는 대표적인 웹 분석 도구이다. 웹사이트나 앱에 제공되는 자바스크립트 트래킹 코드를 삽입하면, 방문자가 사이트에 접속할 때마다 그 행동(페이지 조회, 세션 지속 시간, 이탈률, 전환 등)을 자동으로 기록하고, 이 데이터를 기반으로 다양한 보고서를 생성한다.
BigQuery란?
빅쿼리(BigQuery)는 구글 클라우드 플랫폼에서 제공하는 서버리스 데이터 웨어하우스 서비스이다. 별도의 인프라 관리 없이, SQL을 통해 페타바이트(PB) 규모의 대용량 데이터를 빠르게 저장, 분석, 쿼리할 수 있도록 설계되어 있다.
AARRR 분석이란?
AARRR은 사용자의 서비스 이용흐름을 기반으로 고객 획/ 활성화/ 유지/ 수익/ 추천 이라는 5가지 카테고리를 정의하고 각 카테고리에서 핵심이 되는 지표를 발굴하고 이를 측정/ 개선하는 지표관리 방법론이다.
- Acquisition (획득):
고객이 어떻게 해당 서비스나 제품을 알게 되었는지, 즉 유입 경로(검색, 미디어, 광고 등)를 분석. - Activation (활성화):
첫 방문 후 고객이 긍정적인 경험을 했는지 평가. 예를 들어, 회원 가입, 첫 구매, 앱 내 첫 행동 등이 이에 해당 됨. - Retention (유지):
고객이 제품이나 서비스를 반복적으로 이용하는지를 측정. 즉, 초기 경험 후 얼마나 많은 고객이 돌아오는지를 분석. - Revenue (수익):
고객으로부터 얼마나 수익을 창출할 수 있는지를 파악. 구매, 구독, 광고 클릭 등의 수익 창출 지표를 포함. - Referral (추천):
기존 고객이 다른 사람에게 제품이나 서비스를 추천하는지, 즉 자연스러운 입소문 효과를 분석.
이번 포스팅에서는 데이터 소개와 AARRR의 첫 번째 순서인 Acqusition(획득) 단계에 대해 분석할 것이다.
데이터 확인
- 원본 데이터 : Google Analytics Sample
- 데이터가 수집된 사이트 : Google Merchandise Store
- 기간 : 2016년 8월 1일 ~ 2017년 8월 1일
- 요약 (구글 애널리틱스에서 제공되는 데이터 종류) :
- 트래픽 소스 데이터: 웹사이트 방문자의 출처에 대한 정보(자연 트래픽, 유료 검색 트래픽, 디스플레이 트래픽 등)
- 콘텐츠 데이터: 사이트에서 사용자의 행동에 대한 정보(방문자가 보는 페이지의 URL, 콘텐츠와 상호 작용하는 방식 등)
- 거래 데이터: 웹사이트에서 발생하는 거래에 관한 정보.
- etc.
먼저, 분석에 사용할 데이터를 확인해보자.
from google.cloud import bigquery
import pandas as pd
import numpy as np
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = r"/content/drive/MyDrive/Colab Notebooks/AARRR/aarrr-project-3f905304d852.json"
# Client 객체 생성
client = bigquery.Client()
# 데이터셋 참조경로(reference) 설정
dataset_ref = client.dataset('google_analytics_sample', project='bigquery-public-data')
# 해당 경로로부터 데이터셋 추출
dataset = client.get_dataset(dataset_ref)
# 데이터셋을 테이블 단위로 보기
tables = list(client.list_tables(dataset))
table_names = sorted([t.table_id for t in tables])
# 테이블 단위로 간단한 정보 확인
print(f"""table 개수 : {len(tables)}
tables : {", ".join(table_names[:3])}, ...
date 범위 : {table_names[0][-8:]} ~ {table_names[-1][-8:]}""")
데이터셋은 여러 개의 테이블로 구성되어 있으며, 각 테이블의 컬럼 정보는 다음과 같다.
# 테이블 경로 생성
table_ref_temp = dataset_ref.table(table_names[0])
# 테이블 가져오기
table_temp = client.get_table(table_ref_temp)
# 컬럼 확인
client.list_rows(table_temp, max_results=5).to_dataframe()
아래는 위의 각 스키마가 어떤 데이터로 이루어졌는지 확인하는 과정이다.
def format_schema_field(schema_field, indent=0):
"""
빅쿼리 스키마의 (중첩된 구조 내부까지) 필드 이름과 데이터 타입을 출력하는 함수
"""
indent_str = " " * indent
field_info = f"{indent_str}{schema_field.name} ({schema_field.field_type})"
if schema_field.mode != "NULLABLE":
field_info += f" - {schema_field.mode}"
if schema_field.description:
field_info += f" - {schema_field.description}"
nested_indent = indent + 2
if schema_field.field_type == "RECORD":
for sub_field in schema_field.fields:
field_info += "\n" + format_schema_field(sub_field, nested_indent)
return field_info
# Display schemas
print("SCHEMA field for the 'totals' column:\n")
print(format_schema_field(table_temp.schema[5]))
print()
print("\nSCHEMA field for the 'trafficSource' column:\n")
print(format_schema_field(table_temp.schema[6]))
print()
print("\nSCHEMA field for the 'device' column:\n")
print(format_schema_field(table_temp.schema[7]))
print()
print("\nSCHEMA field for the 'geoNetwork' column:\n")
print(format_schema_field(table_temp.schema[8]))
print()
print("\nSCHEMA field for the 'customDimensions' column:\n")
print(format_schema_field(table_temp.schema[9]))
print()
print("\nSCHEMA field for the 'hits' column:\n")
print(format_schema_field(table_temp.schema[10]))
Acquisition (획득)
사용자들을 어떻게 데려올 것인가?
사용자를 우리 서비스로 데려오는 것과 관련된 활동. 즉, 신규 고객이 생기는 것을 의미한다.
Aquisition의 핵심은 고객 유치에 기여(Attribution)한 채널의 성과를 판단할 수 있는 모델을 만드는 것이다.
어떤 채널을 통해 들어온 사용자들이 꾸준히 남아서 활동하는지, 결제로 전환되는 비율이 얼마나 되는지 등을 바탕으로 각 채널의 가치를 정확히 판단할수 있어야 이를 기반으로 전체적인 전략을 수립하거나 예산을 분배할 수 있기 때문이다.
KPI
방문자 수, 유입 경로, 전환율, 이탈율
1. 유입 경로
(1) 최다 유입 경로
# 유입이 가장 많이 된 경로 탑 10 쿼리 작성
query = f"""
SELECT
trafficSource.source AS source,
count(*) AS visit_count
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170801'
GROUP BY
source
ORDER BY
visit_count DESC
LIMIT 10
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_inflow = query_job.to_dataframe()
# 결과 출력
df_inflow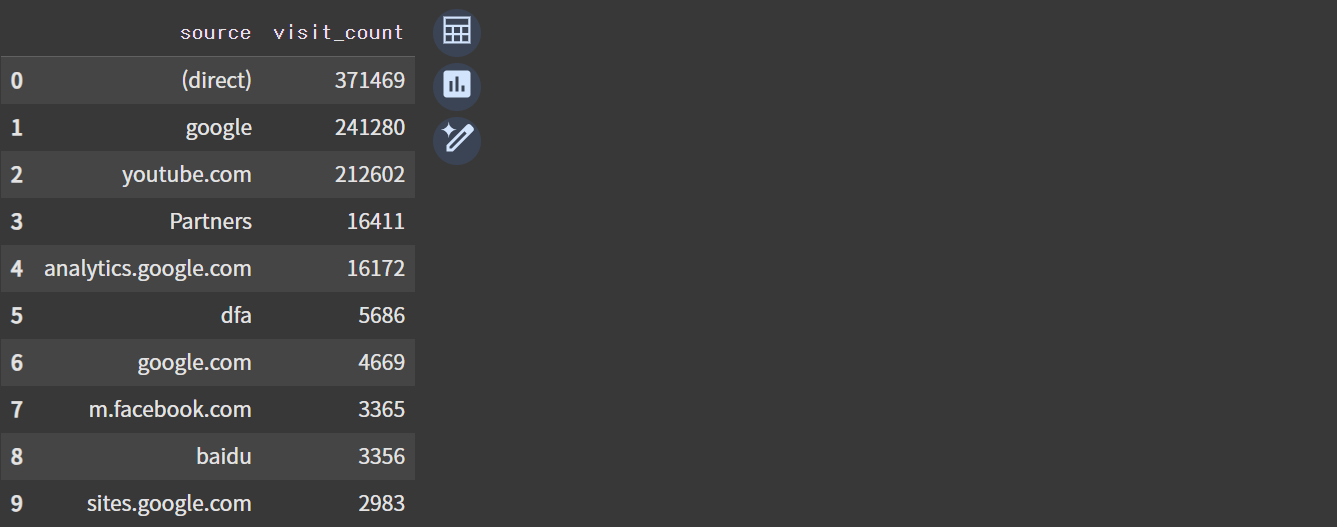
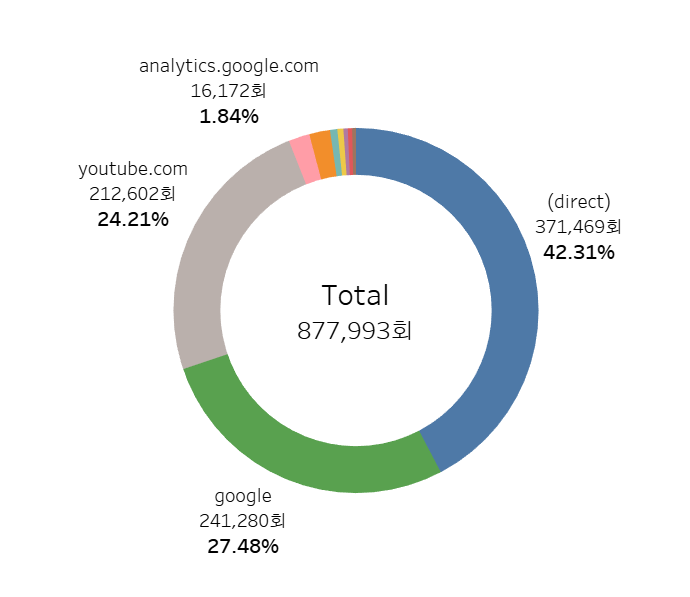
직접 접근한 경우(direct)와 구글, 유튜브가 대부분의 유입 경로를 차지하고 있다.
(2) 월별 유입 경로
# 월별 유입 경로 분석 쿼리 작성
query = """
WITH
grouped AS (
SELECT
SUBSTR(_TABLE_SUFFIX, 1, 6) AS month,
trafficSource.source AS source,
COUNT(*) AS visit_count
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170731'
GROUP BY
SUBSTR(_TABLE_SUFFIX, 1, 6), trafficSource.source
),
ranked AS (
SELECT
month,
source,
visit_count,
ROW_NUMBER() OVER (
PARTITION BY month
ORDER BY visit_count DESC
) AS rn
FROM
grouped
)
SELECT
month,
source,
visit_count
FROM
ranked
WHERE
rn <= 5
ORDER BY
month, visit_count DESC;
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_monthly = query_job.to_dataframe()
# 결과 출력
df_monthly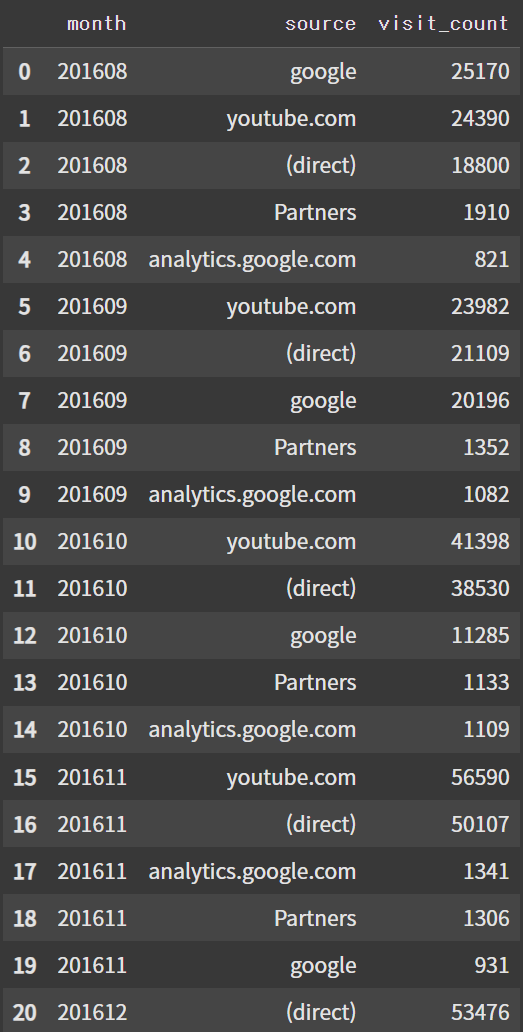
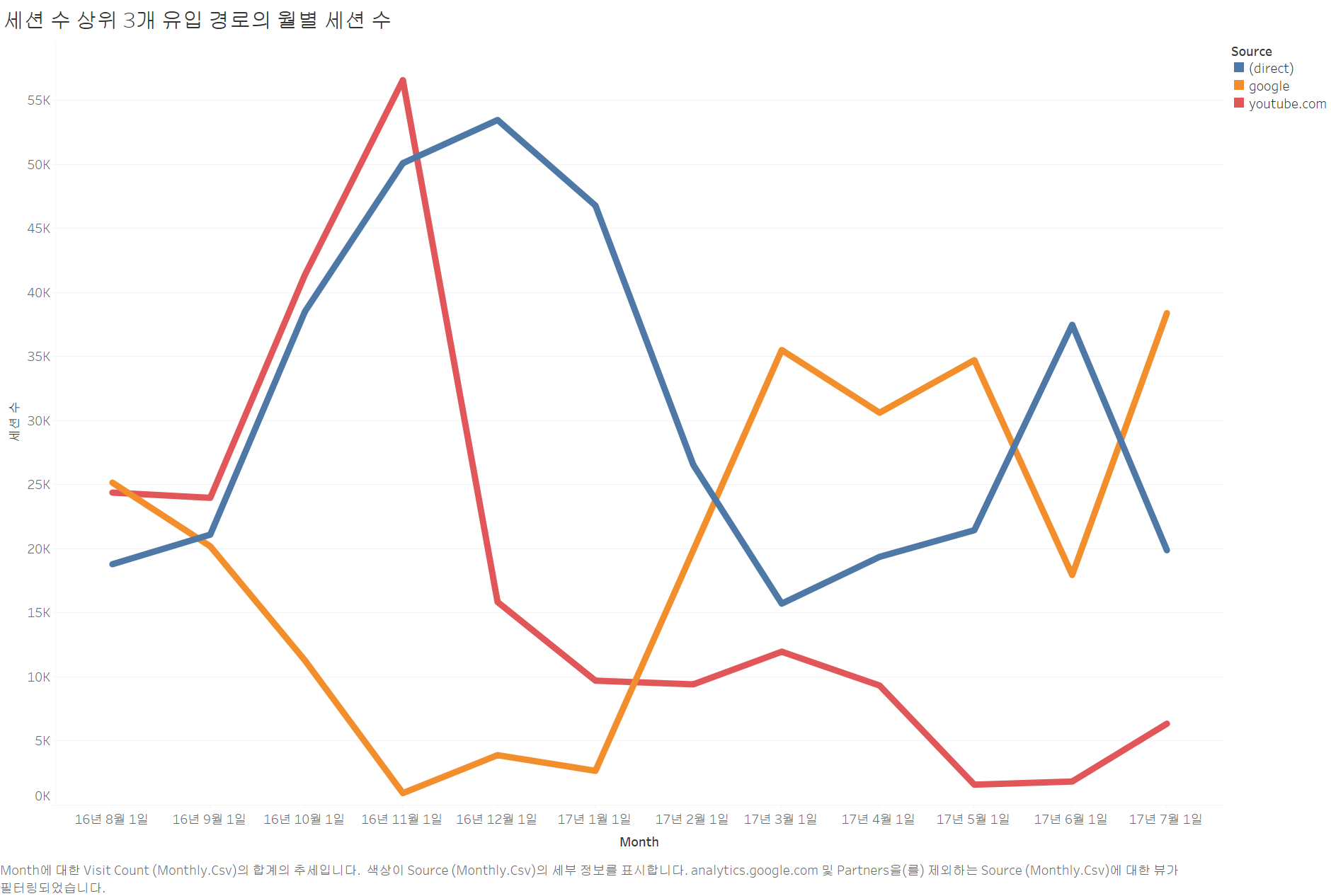
(3) 유입 경로별 신규/재방문자의 비율
# 유입 경로별 신규 방문자, 재방문자 비율 분석 쿼리 작성
# 이때, totals.newVisit 변수의 경우 신규 방문자는 1, 재방문자는 NULL이다.
query = """
SELECT
trafficSource.source AS source,
COUNT(*) AS visit_count,
SUM(CASE WHEN totals.newVisits = 1 THEN 1 ELSE 0 END) / COUNT(*) AS new_visitors_rate,
SUM(CASE WHEN totals.newVisits = 1 THEN 0 ELSE 1 END) / COUNT(*) AS returning_visitors_rate
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170731'
GROUP BY
source
ORDER BY
visit_count DESC
LIMIT 10
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_visit = query_job.to_dataframe()
# 결과 출력
df_visit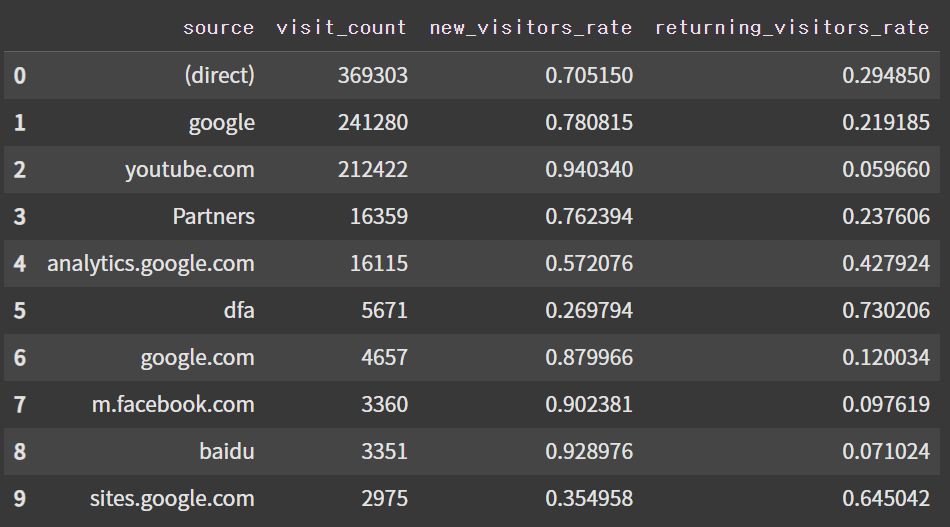
- dfa: Google의 DFA(Campaign Manager 360의 이전 버전) 광고 캠페인에서 유입
- sites.google.com: 다른 사용자가 만든 Google Sites 페이지에 판매자의 웹사이트 링크가 포함되어 있어, 해당 링크를 통해 방문자가 유입 (이번 분석에서 판매자는 Goolge Merchandise Store)
(4) 유입 경로별 체류 시간
- 정규분포를 따르지 않고 이상치가 존재
- 그러므로 평균이 아닌 중앙값 사용
- totals.timeOnScreen: 사용자가 웹사이트에서 머문 총 시간을 초 단위로 나타낸 변수
# 유입 경로별 체류 시간 분석 쿼리 작성
query = """
SELECT
trafficSource.source AS source,
COUNT(*) AS visit_count,
APPROX_QUANTILES(totals.timeOnSite, 100)[SAFE_ORDINAL(50)] AS median_sreen_time
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170801'
GROUP BY
source
ORDER BY
visit_count DESC
LIMIT 11
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_timeOnScreen = query_job.to_dataframe()
# 결과 출력
df_timeOnScreen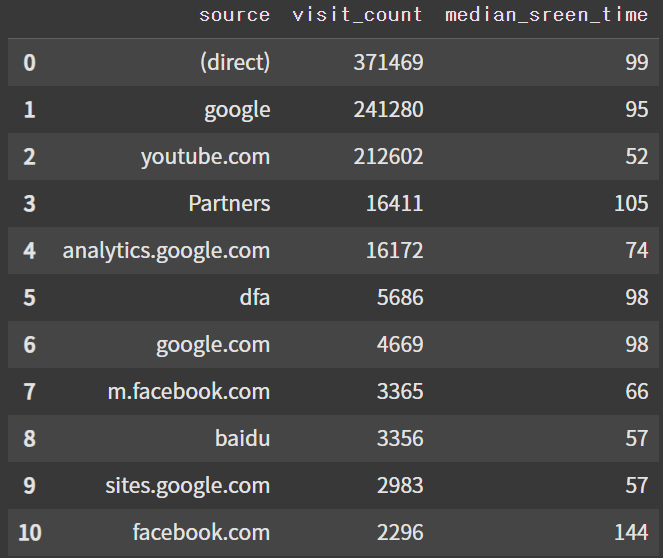
- Partner: Google과 제휴 관계에 있는 타사 플랫폼이나 서비스를 통해 유입된 트래픽
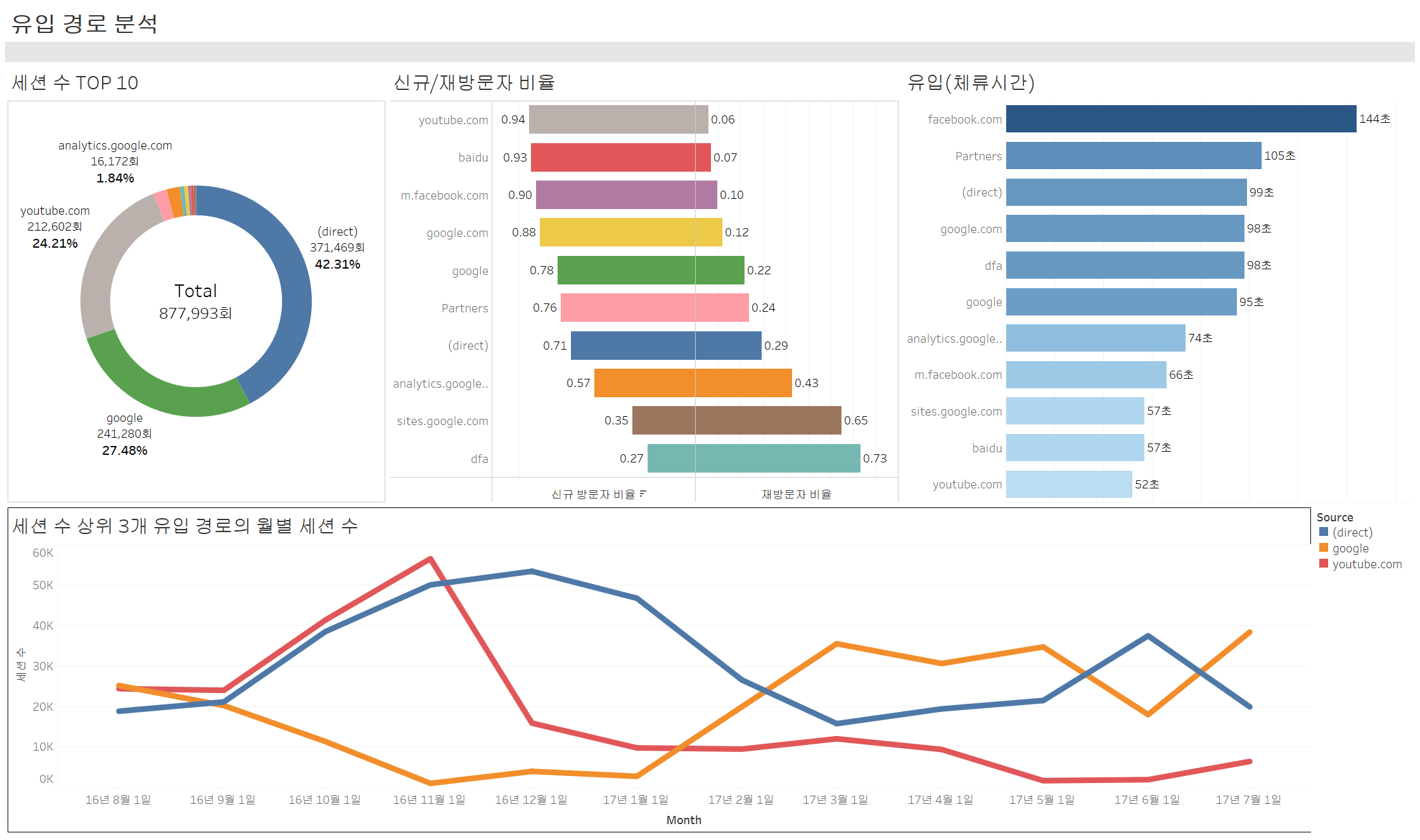
위의 결과로 태블로 대시보드를 제작해보았다.
2. 캠페인별 세션 수
# 캠페인별 세션 수 분석 쿼리 작성
query = """
SELECT
trafficSource.campaign AS campaign,
COUNT(*) AS visit_count,
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170801'
GROUP BY
campaign
ORDER BY
visit_count DESC
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_campaign = query_job.to_dataframe()
# 결과 출력
df_campaign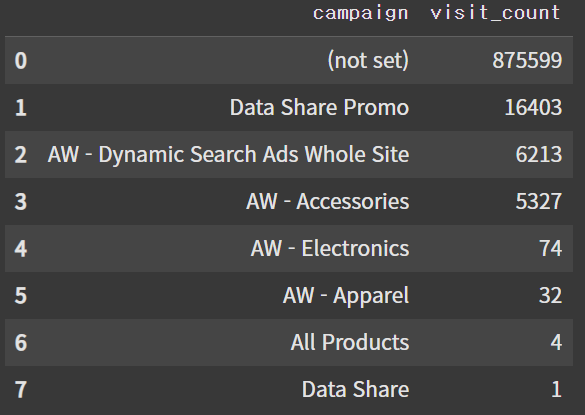
3. 방문 매체별 세션 수
# 방문 매체별 세션 수 분석 쿼리 작성
query = """
SELECT
trafficSource.medium AS medium,
COUNT(*) AS visit_count,
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170801'
GROUP BY
medium
ORDER BY
visit_count DESC
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_medium = query_job.to_dataframe()
# 결과 출력
df_medium
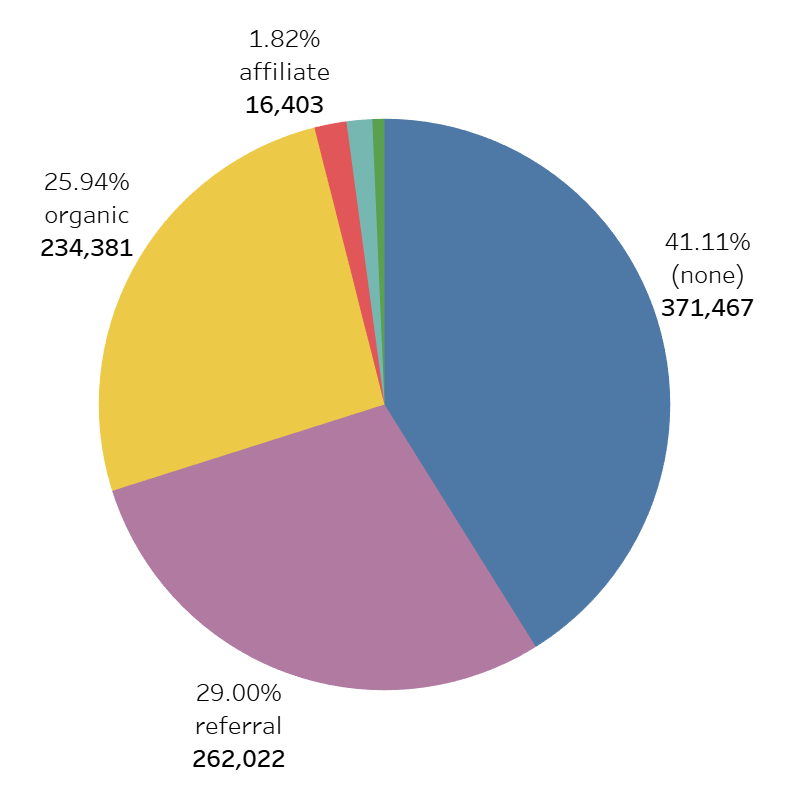
스키마 trafficSource.medium의 구성 요소
none
- 보통 직접 방문(Direct Traffic)을 의미.
- 사용자가 URL을 직접 입력하거나 즐겨찾기를 통해 접속하는 경우, 캠페인 정보 없이 medium이 "(none)"으로 표시됨.
referral
- 다른 웹사이트에서 링크를 통해 유입된 트래픽.
- 방문자가 외부 사이트의 링크를 클릭해 도착한 경우 medium이 "referral"로 설정됨.
organic
- 유료 광고가 아닌, 검색엔진의 자연 검색 결과(Organic Search)에서 유입된 트래픽.
- 구글, 네이버, 빙 등에서 자연 검색 결과로 방문했을 때 medium은 "organic".
affiliate
- 제휴(affiliate) 마케팅을 통해 유입된 트래픽.
- 제휴 프로그램 링크를 통해 방문한 경우 이 값이 사용됨.
cpc
- 클릭당 비용(Cost Per Click) 광고를 통해 유입된 트래픽.
- 구글 애즈와 같은 유료 검색 캠페인에서 클릭을 통해 방문한 경우 medium은 "cpc".
cpm
- 천 회 노출당 비용(Cost Per Mille) 광고를 통해 유입된 트래픽.
- 노출 기반의 광고 캠페인에서 유입된 트래픽의 경우 "cpm"이 사용될 수 있다.
not set
- 캠페인 매개변수나 추적 정보가 제대로 전달되지 않아, medium 값이 설정되지 않은 경우에 나타남.
- 설정 오류나 데이터 누락 등으로 인해 "not set"으로 표시됨.
4. 국가별 세션 수
# 국가별 세션 수 분석 쿼리 작성
query = """
SELECT
geoNetwork.country AS country,
COUNT(*) AS visit_count,
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170801'
GROUP BY
country
ORDER BY
visit_count DESC
LIMIT 10
"""
# 쿼리 실행 및 데이터 가져오기
query_job = client.query(query)
df_country = query_job.to_dataframe()
# 결과 출력
df_country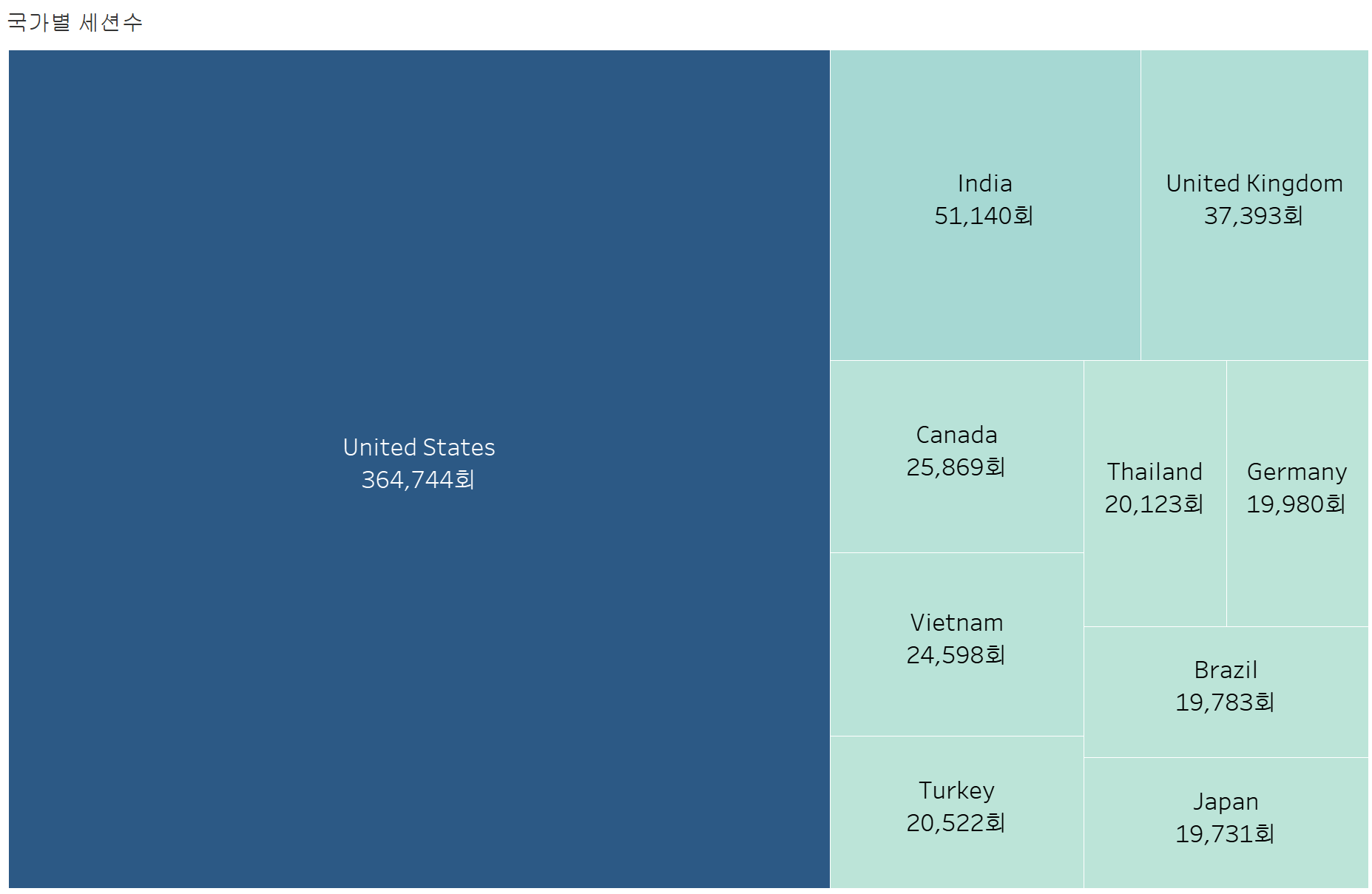
인사이트
1. 유입 경로 분석 (세션 수 기준)
- 총 세션 수: 877,993회
- 최다 유입 경로:
- (direct) (42.31%) > google (27.48%) > youtube.com (24.21%)
- 직접 방문 (direct)이 가장 높은 비중을 차지, 브랜드 인지도가 높거나 즐겨찾기 활용 가능성이 큼
- google, youtube를 통한 유입이 많아 검색 및 콘텐츠 기반 유입이 중요
2. 신규 방문자 vs 재방문자 비율
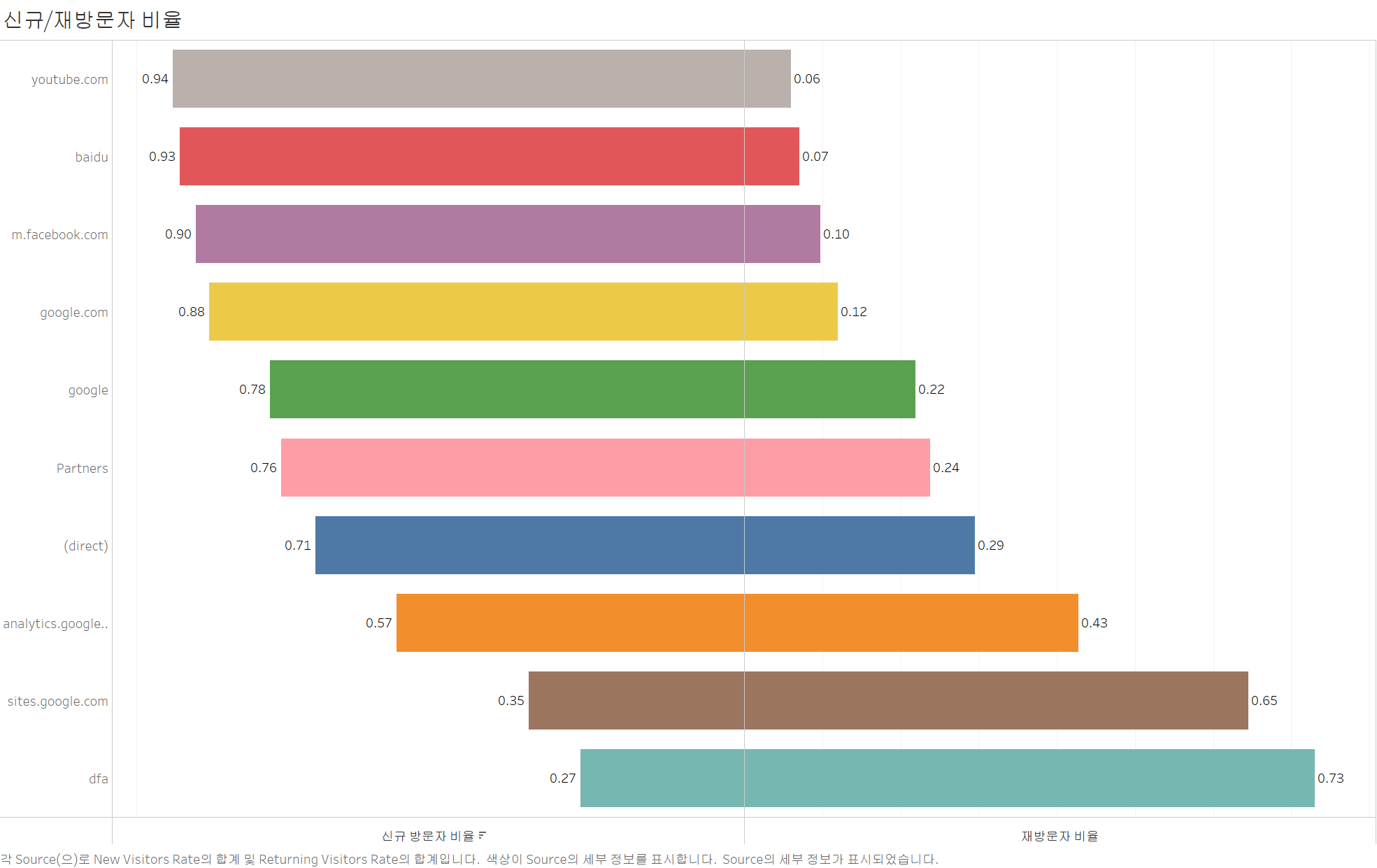
- youtube.com과 baidu를 통해 들어온 방문자는 신규 방문자 비율(0.94, 0.93)이 매우 높음
- 반면 dfa, sites.google.com 등은 재방문자 비율(0.73, 0.65)이 상대적으로 높음
- 검색 및 추천(YouTube, Baidu) 기반 유입은 신규 유저가 많음 → 콘텐츠 최적화 필요
- dfa, sites.google.com의 경우 광고 캠페인이 특정 관심사를 가진 타깃 그룹에게 노출될 가능성이 있고, 특히 dfa의 경우 리마케팅 캠페인을 통해 기존 방문자에게 다시 다가가는 전략이 작동하여 재방문율이 높음 → 충성도 높은 고객 관리 필요
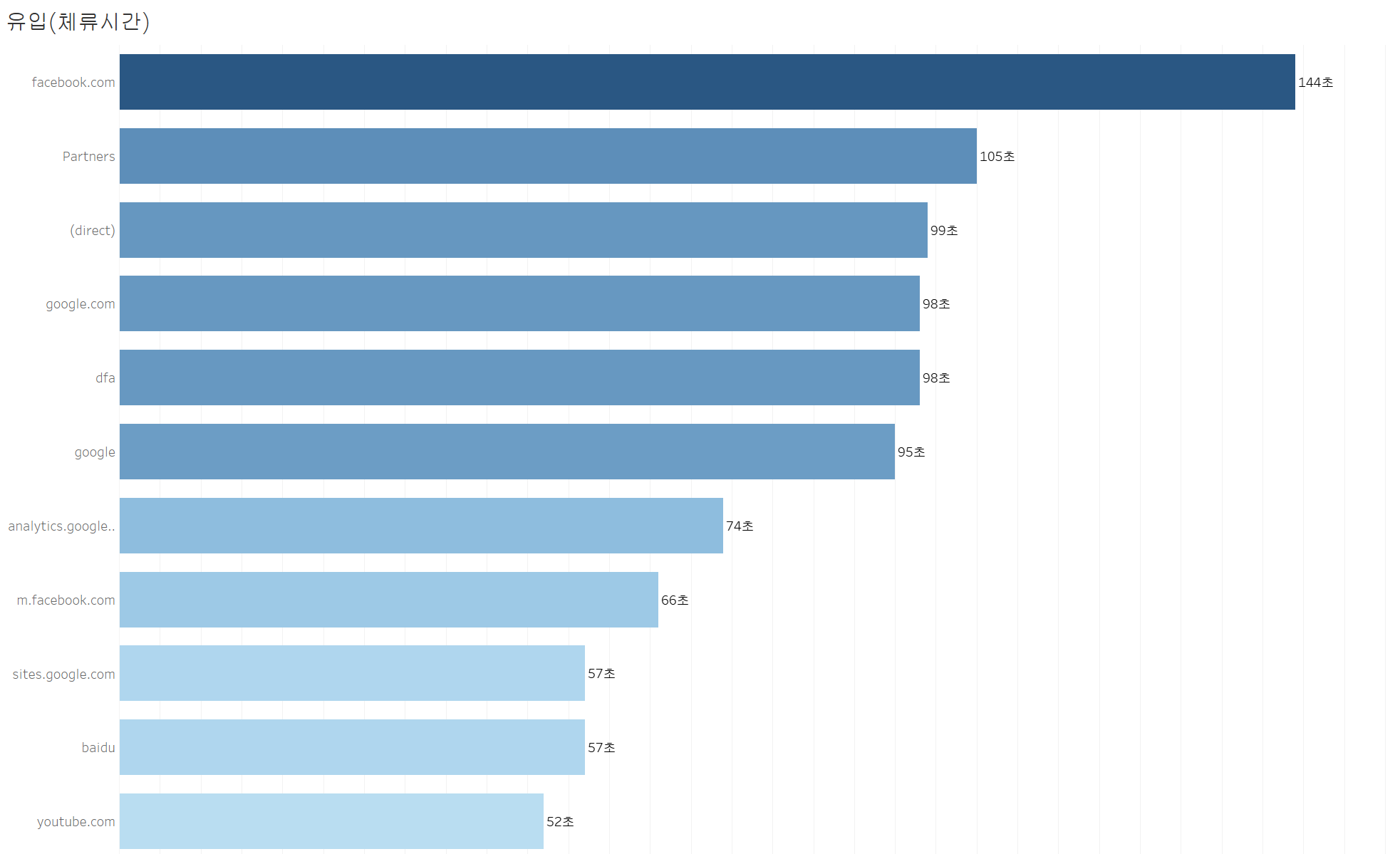
3. 유입 경로별 체류 시간 분석
- facebook.com (144초) > Partners (105초) > (direct) (99초) 순으로 체류 시간이 김
- youtube.com은 체류 시간이 52초로 가장 짧음
- 유튜브는 신규 방문자가 많지만, 체류 시간이 짧아 즉각적인 이탈 가능성이 있음
- 반면, facebook.com은 체류 시간이 가장 길어, 콘텐츠 소비 시간이 김
4. 방문 매체별 세션 수 분석
- (none), referral, organic 방문이 압도적으로 많음
- 광고 유입 (cpc: 13,079, cpm: 6,184) 비중이 낮음
- 유료 광고보다는 자연 검색 및 추천을 통한 유입이 많음
- 광고 최적화(ROAS 분석) 필요
5. 국가별 방문자 분석
- United States (364,744)이 가장 많고, India (51,140), United Kingdom (37,393) 순
- 미국 유저 비율이 압도적 → 미국 시장 맞춤형 콘텐츠 필요
- 아시아 국가(Vietnam, Thailand, Japan) 유입도 존재 → 다국적 타겟팅 고려 가능
참조 노트북



