Kaggle에 있는 Global Video Game Sales and Reviews 데이터셋으로 전처리 및 시각화를 해보겠습니다.
EDA 주제는 다음과 같습니다
① 각 플랫폼 별 발매 게임 수
② 평점 TOP 10 게임
③ 지역별 인기 장르 TOP 3 게임 ( North.America, Europe, Japan)
④ 각 지역의 연도별 판매량 변화 추이
⑤ 지역별 총 판매량 비율
https://www.kaggle.com/datasets/thedevastator/global-video-game-sales-and-reviews?resource=download
Global Video Game Sales and Reviews
Global Video Game Performance: Sales, Reviews, and Rankings
www.kaggle.com
먼저 위 주소에서 데이터를 다운로드한 후 Rstudio에서 csv 파일을 읽습니다.
# 데이터 불러오기
setwd('C:\\Users\\32217778\\Downloads\\archive')
ds = read.csv('C:\\Users\\32217778\\Downloads\\archive\\Video_Games_Sales.csv')
sum(is.na(ds)) # 결측치 확인
ds = na.omit(ds)[,c(-1)] # 결측치, 'index' 열 제거
head(ds)
str(ds)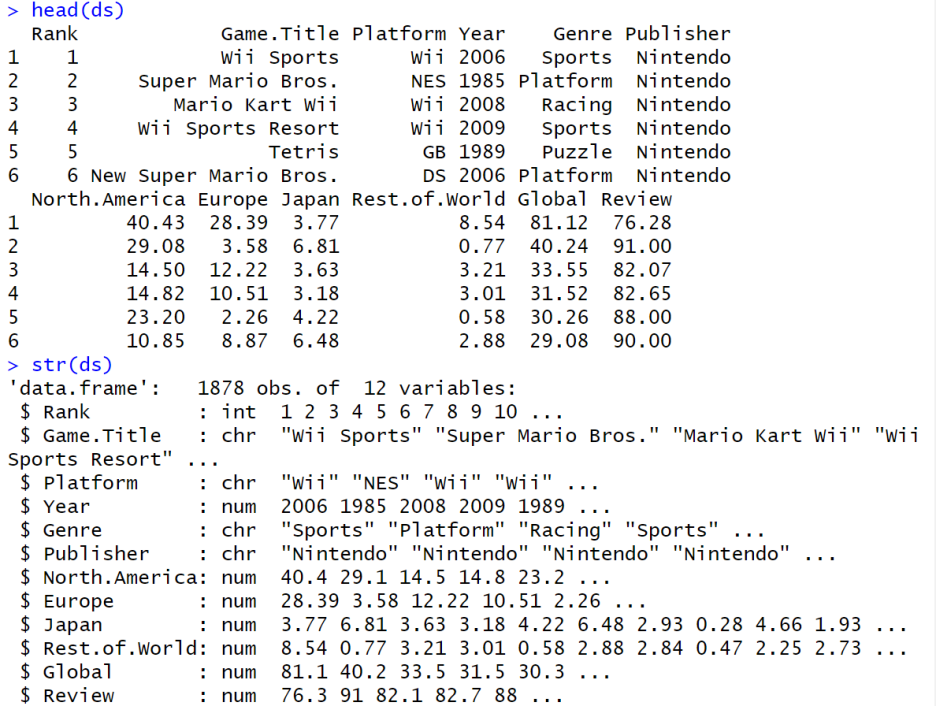
① 각 플랫폼 별 발매 게임 수
Platform = as.factor(ds$Platform) # 각 범주를 정수로 인코딩
install.packages('ggplot2') # ggplot 사용을 위해 ggplot2 패키지 설치
library(ggplot2)
ggplot(ds, aes(x = Platform, fill = Platform)) +
geom_bar() +
labs(x = '', y = '',
title = 'Number of Games Released by Platform') +
theme(legend.position = "none",
axis.text.x = element_text(angle = 45, vjust = 0.5, hjust=1))
ggplot : 데이터 프레임 'ds'를 기반으로 ggplot 객체를 생성한 후, x 축은 Paltform 열을 나타내도록 하고, Platform 열을 이용하여 그래프 색을 채우도록 설정합니다.
geom_bar : 각 플랫폼에 대한 막대그래프를 생성합니다.
labs : x 축, y 축, 그래프 제목을 지정합니다.
theme : 그래프의 테마를 설정하는 함수입니다.
범례를 표시하지 않도록 legend.position = "none"으로 설정하고, x 축 레이블을 45도 각도로 회전시키고,
수직 정렬을 조절하여 가독성을 높입니다.
- 실행 결과

② 평점 TOP 10 게임
install.packages('dplyr') # 파이프 연산자 사용을 위해 'dplyr' 패키지 설치
library(dplyr)
top_10_review = ds %>% # 데이터프레임 'ds'에서
arrange(desc(Review)) %>% # Review 열을 내림차순으로 정렬하고,
head(10) # 상위 10개의 행만 선택
top_10_review[,2] # Game.Title열만 선택
- 실행 결과

③ 지역별 인기 장르 TOP 3 게임 ( North.America, Europe, Japan)
install.packages("tidyr") # 데이터 형태를 재구성하고 정돈하는 패키지
library(tidyr)
# TOP 3 데이터프레임 만들기
#---# [ds 데이터프레임을 장르를 기준으로 그룹화]
top_3_genre = ds %>% group_by(Genre) %>%
#---# [각 장르의 지역 별 판매량 총계 계산]
summarise(North.America = sum(North.America), Europe = sum(Europe),
Japan = sum(Japan)) %>%
#---# [tidy 데이터 형식으로 변환 (넓은 형태 -> 긴 형태)]
pivot_longer(cols = c('North.America', 'Europe', 'Japan'),
names_to = 'Region', values_to = 'Sales') %>%
#---# [장르별 판매량을 내림차순으로 정렬]
arrange(Genre, desc(Sales)) %>%
#---# [다시 한 번 Genre 열을 기준으로 그룹화]
group_by(Genre) %>%
#---# [각 그룹에서 상위 3개의 행 선택]
slice_head(n = 3)
#---# [각 지역별 TOP3 추출]
top_3_genre = top_3_genre[1:9,]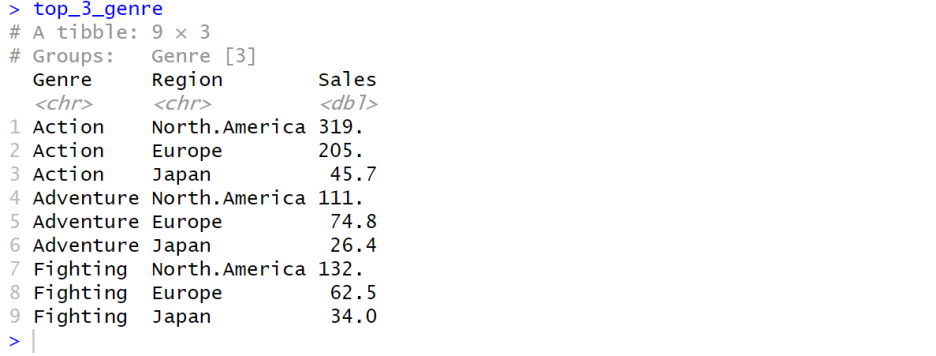
만든 데이터 프레임을 ggplot을 사용하여 시각화합니다.
ggplot(top_3_genre, aes(x = Genre, y = Sales, fill = Region)) +
geom_bar(stat = "identity", position = "dodge") +
labs(title = "Top 3 Genres by Sales in Each Region",
x = "", y = "") +
theme_minimal() +
facet_wrap(~ Region, scales = "free_y", nrow = 1) +
theme(legend.position = "none",
axis.text.x = element_text(angle = 45, vjust = 0.5, hjust=1))
ggplot : 데이터 프레임 'top_3_genre'을 기반으로 ggplot 객체 생성 후, x 축은 장르, y 축은 총 판매량, 막대 색은 지역 별로 설정합니다.
geom_bar : 데이터 셋에 있는 변수의 값이 막대의 높이가 되도록 stat = "identity"으로 설정하고, 막대를 나란히 그리도록 position = "dodge"으로 설정합니다.
facet_wrap : Region 변수를 기준으로 패널을 생성하고, 각 패널마다 y 축의 스케일을 자유롭게 설정하기 위해 free_y으로 설정하고, 행의 개수를 1로 설정하여 패널이 한 행에만 나타나도록 nrow = 1으로 합니다.
- 실행 결과
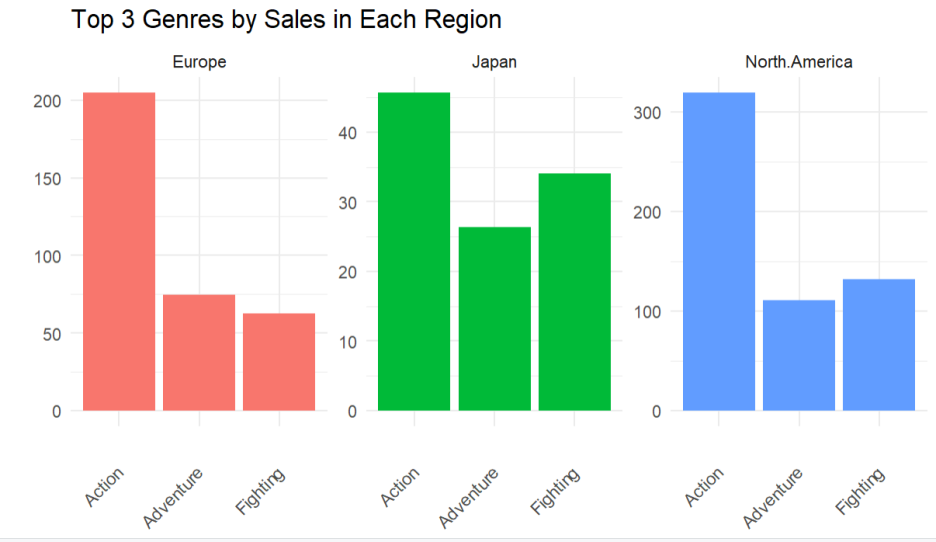
지역에 상관없이 액션 장르의 인기가 가장 많은 것을 알 수 있습니다.
④ 각 지역의 연도별 판매량 변화 추이
#---# [ds 데이터프레임을 연도별로 그룹화]
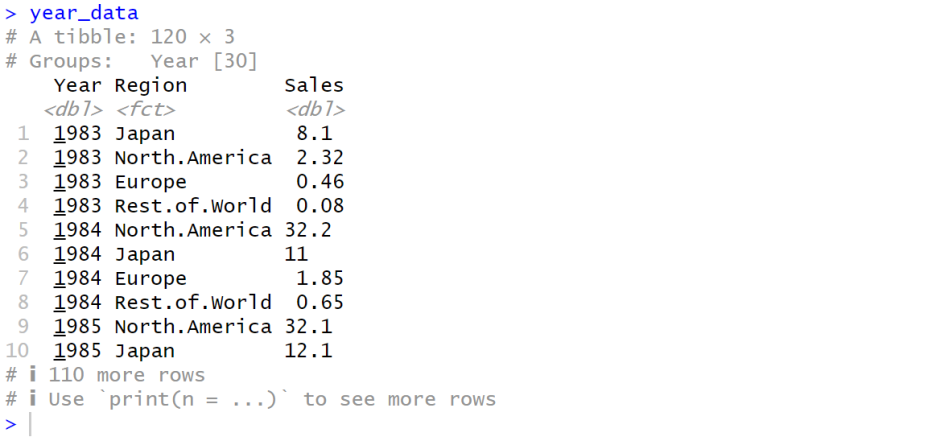
year_data = ds %>% group_by(Year) %>%
#---# [각 그룹에서 지역별 합계 계산]
summarize(North.America = sum(North.America), Japan = sum(Japan),
Europe = sum(Europe), Rest.of.World = sum(Rest.of.World)) %>%
#---# [각 지역의 판매량을 Region 열에, 해당 판매량을 Sales 열에 저장]
pivot_longer(cols = c('North.America', 'Japan', 'Europe', 'Rest.of.World'),
names_to = 'Region', values_to = 'Sales') %>%
#---# [연도별로 판매량을 내림차순 정렬]
arrange(Year, desc(Sales)) %>%
#---# [다시 한 번 연도별로 그룹화]
group_by(Year)
# Region 변수를 factor로 변환하고 원하는 순서로 지정 (범례 순서 지정)
year_data$Region = factor(year_data$Region,
levels = c("North.America", "Europe", "Japan", "Rest.of.World"))
year_data
- 실행 결과
# ggplot으로 시각화
ggplot(year_data, aes(x = Year, y = Sales)) +
geom_line(aes(color = Region), lwd = 1) +
scale_x_continuous(breaks = seq(1985, 2010, 5)) +
scale_y_continuous(breaks = seq(0, 175, 25)) +
labs(x = '', y = 'Total Sales (M)', title = "Regional Sales by Year") +
scale_color_manual(values = c("North.America" = "skyblue",
"Europe" = "yellowgreen",
"Japan" = "pink",
"Rest.of.World" = 'grey'))- 실행 결과
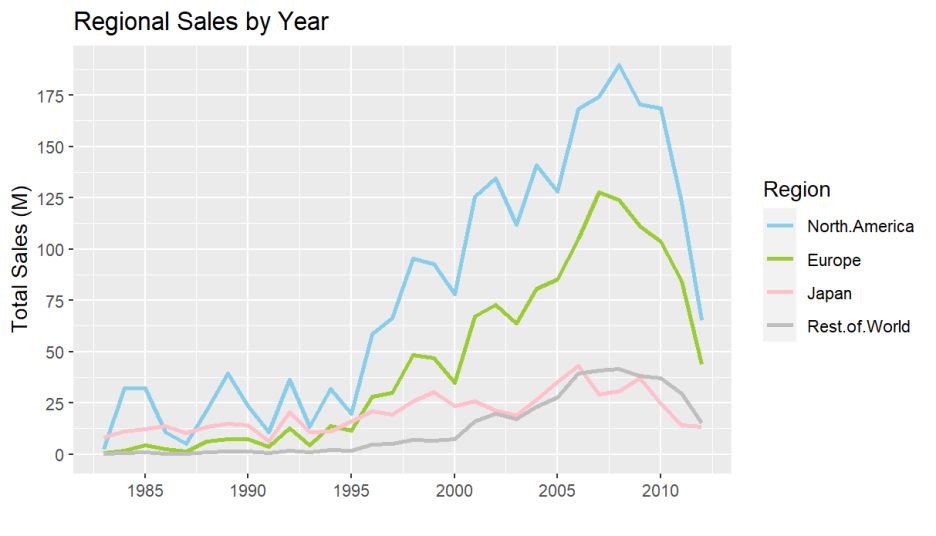
1980년부터 2000년대 후반까지 꾸준히 상승하다가 2010년 이후로 급감하는 것으로 보이는데,
이는 온라인 컴퓨터 게임 시장 활성화의 영향이 컸을 것으로 예상됩니다.
⑤ 지역별 총 판매량 비율
Region = ds[,c(7,8,9,10)]
tot_sales = apply(Region, 2, sum) # 지역별 총합 구하기
ratio_data = data.frame(Region = c("North.America", "Europe", "Japan", "Rest.of.World"),
tot_Sales = apply(Region, 2, sum),
ratio = round(tot_sales / sum(tot_sales) * 100, 1))
# Region 변수를 factor로 변환하고 원하는 순서로 지정 (범례 순서 지정)
ratio_data$Region = factor(ratio_data$Region,
levels = c("North.America", "Europe", "Japan", "Rest.of.World"))
ggplot(ratio_data, aes(x = '', y = tot_Sales, fill = Region)) +
geom_bar(width = 5, stat = "identity") +
coord_polar("y") +
theme_void() +
geom_text(aes(label = paste0(ratio, "%")),
position = position_stack(vjust = 0.5)) +
labs(title = "Ratio of Sales by Region") +
scale_fill_manual(values = c("North.America" = "skyblue",
"Europe" = "yellowgreen",
"Japan" = "pink",
"Rest.of.World" = 'grey'))
ggplot : ggplot 객체를 생성하고, fill = Region_name으로 지역에 따라 색을 지정합니다.
geom_bar : 막대를 그리는데, width 옵션으로 막대의 넓이를 조절하고, stat = "identity" 으로 실제 데이터 값을 사용합니다.
coord_polar("y") : 극 좌표계를 사용하여 파이 차트를 생성합니다
theme_void : 배경을 투명하게 만들어 전체적인 디자인을 설정합니다.
geom_text : 그래프 위에 비율을 나타내는 텍스트를 추가하고, vjust를 통해 텍스트의 세로 위치를 조절합니다.
- 실행 결과

데이터 제공
Andy Bramwell in Kaggle (@bramwax)
'R' 카테고리의 다른 글
| [R] 다변량 자료 분석 (2) : Hotelling T^2 검정 (2) | 2024.03.21 |
|---|---|
| [R] 다변량 자료 분석 (1) : airquality 데이터 산점도 (0) | 2024.03.21 |
| [R] 데이터 전처리 및 시각화 (4) (0) | 2024.02.23 |
| [R] 데이터 전처리 및 시각화 (3) (0) | 2024.01.23 |
| [R] 데이터 전처리 및 시각화 (2) (1) | 2024.01.23 |



