Kaggle에 있는 Life Expectancy 데이터 셋으로 전처리 및 시각화를 해보겠습니다.
EDA 주제는 다음과 같습니다.
① 나라별 평균 기대 수명의 분포
② 평균 기대 수명 상위/하위 5개국
③ 평균 기대 수명 세계 지도
④ 연도별 평균 기대 수명 변화 추이
먼저 위 주소에서 데이터를 다운로드한 후 Rstudio에서 csv 파일을 읽습니다.
setwd('C:\\Users\\32217778\\Downloads\\life_expectancy')
ds = read.csv('C:\\Users\\32217778\\Downloads\\life_expectancy\\life_expectancy.csv')
table(is.na(ds))

파일을 읽고 결측치를 확인한 결과 1694개 행에 결측치가 포함되어 있었고, colsums 함수로 확인해 보니
colSums(is.na(ds))
결측치는 모두 Code 칼럼에 존재했습니다.
결측치 제거 필요성을 확인하기 위해 데이터 형태를 보겠습니다.
str(ds)
head(ds)
Code 칼럼은 Entity 칼럼의 나라 이름을 간단히 줄인 데이터이므로, 결측값이 있어도 위에서 정한 EDA 과정에 큰 영향을 미치지 않는다고 판단해서 제거하지 않았습니다.
① 나라별 평균 기대 수명의 분포
aggregate 함수로 나라별 평균 기대 수명을 구하고 시각화해보겠습니다.
avg_le = aggregate(ds$LifeExpectancy, by = list(Country = ds$Entity), mean)
head(avg_le)
summary(avg_le$x)
boxplot(avg_le$x, col = 'skyblue', main = 'Average Life Expectancy')


avg_le 데이터 프레임의 분포를 상자 그림으로 보니 하단에 이상치가 한 개 보이고, 이는 평균 기대 수명의 최솟값임을 알 수 있습니다.
이제 이 이상치를 확인해 보겠습니다.
avg_le[avg_le$x == min(avg_le$x),] # 확인해보니 USSR (소련)
ds[ds$Entity == 'USSR',] # 1900, 1913 두 해의 데이터 뿐이다
ds = ds[-c(19206, 19207),] # 소련 행 제거
확인해 보니 USSR(소련) 국가의 데이터였고

2개의 행밖에 없는 것을 확인했으므로 이후의 정확한 분석을 위해 이상치를 제거했습니다.
avg_le = aggregate(ds$LifeExpectancy, by = list(Country = ds$Entity), mean)
boxplot(avg_le$x, col = 'skyblue', main = 'Average Life Expectancy')avg_le를 다시 선언하고, 상자 그림을 통해 분포를 다시 확인해 보겠습니다.

상자 그림으로 확인해 보니 이상치가 제거된 모습이고, 아래쪽 수염이 긴 것으로 보아 왼쪽 꼬리가 긴 형태의 분포인 것으로 보입니다.
hist 함수를 사용해 히스토그램으로 시각화해보겠습니다.
hist(avg_le$x, breaks = 15, col = 'skyblue',
xlab = 'LifeExpectancy', main = 'Avg_LifeExpectancy')
히스토그램으로 확인한 결과 정규분포가 아닌 오른쪽으로 치우친 (왼쪽 꼬리가 긴) 형태의 분포임을 알 수 있습니다.
소련처럼 비정상적인 데이터를 제외하기 위해 1950년 이후의 데이터만 취급하겠습니다.
ds = subset(ds, Year >= 1950)이제 평균 기대 수명이 가장 긴 나라와 가장 짧은 나라를 알아보겠습니다.
avg_le = aggregate(ds$LifeExpectancy, by = list(Country = ds$Entity), mean)
avg_le[avg_le$x == max(avg_le$x),] # 아이슬란드(77.31세)
avg_le[avg_le$x == min(avg_le$x),] # 남수단(38.03세)
ds 데이터 프레임을 수정했으니 avg_le를 다시 선언하고, 최댓값과 최솟값을 구한 결과
아이슬란드의 평균 기대 수명이 77.31세로 가장 길었고 남수단이 38.03세로 가장 짧았습니다.
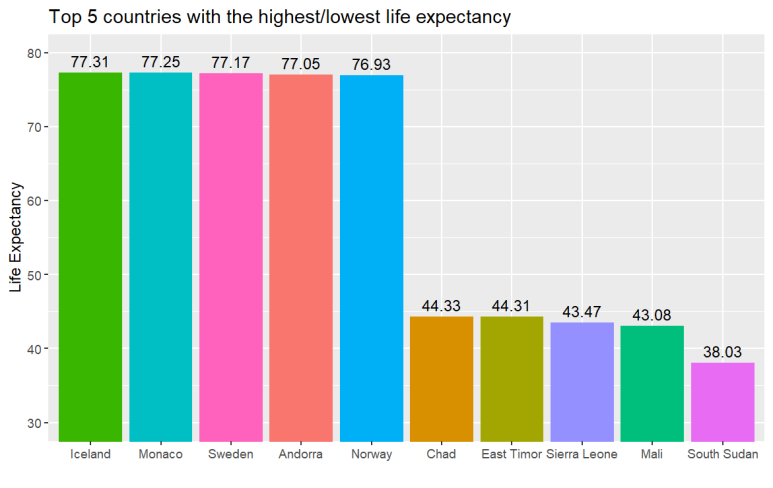
② 평균 기대 수명 상위/하위 5개국
library(dplyr)
high_le = avg_le %>%
arrange(desc(x)) %>%
slice_head(n = 5)
low_le = avg_le %>%
arrange(x) %>%
slice_head(n = 5)
high_low_le = rbind(high_le, low_le)
파이프 연산자 사용을 위해 라이브러리에서 "dplyr" 패키지를 로드합니다.
high_le : 나라별 평균 기대 수명을 내림차순으로 정렬하고, 상위 5개 항목만 선택합니다.
low_le : 나라별 평균 기대 수명을 오름차순으로 정렬하고, 상위 5개 항목만 선택합니다. (오름차순이 디폴트)
high_low_le : 만든 두 리스트를 열로 결합합니다. (1열은 국가명, 2열은 평균 기대 수명)
library(ggplot2)
ggplot(high_low_le, aes(reorder(Country, -x), x, fill = Country)) +
geom_bar(stat = "identity") +
coord_cartesian(ylim = c(30, 80)) +
geom_text(aes(label = round(x, 2)), vjust = -0.5) +
theme(legend.position = 'none') +
labs(x = '', y = 'Life Expectancy',
title = 'Top 5 countries with the highest/lowest life expectancy')
aes(reorder(Country, -x), x, fill = Country) : 나라를 x 값의 내림차순으로 정렬하고, x를 y 축의 값으로 하며, 나라를 기준으로 막대의 색을 채웁니다.
coord_cartesian(ylim = c(30, 80)) : 그래프의 y 값 범위를 30 ~ 80으로 설정합니다.
geom_text(aes(label = round(x, 2)), vjust = -0.5) : 각 막대 위에 해당 나라의 평균 기대 수명을 표기합니다.
③ 평균 기대 수명 세계 지도
country = ds %>%
group_by(Entity) %>%
summarise('LifeExpectancy' = mean(LifeExpectancy))
country = data.frame(country)
head(country)
country : 나라를 기준으로 한 기대 수명의 평균을 계산한 LifeExpectancy 열을 갖는 리스트입니다.
그리고 이후에 left_join 함수 사용을 위해 동일한 형식(데이터 프레임)으로 맞추는 작업을 합니다.

다음으로 세계 지도 데이터를 작업하겠습니다.
library(tidyverse)
world = map_data(map = 'world')
world = world %>%
filter(region != 'Antarctica') # 남극 제외
world = left_join(world, country, by = c('region' = 'Entity'))
world
map_data(map = 'world') : map_data 함수를 이용해 세계 데이터를 world 변수에 저장합니다.
filter(region != 'Antarctica') : 남극은 데이터가 없고 지도 하단에 위치한 면적이 크기 때문에 제외합니다.
left_join(world, country, by = c('region' = 'Entity')) : left_join 함수를 사용해 world 데이터 프레임의 'region'열과 country 데이터 프레임의 'Entity' 열이 일치하는 행들을 결합합니다.
- 실행 결과

마지막으로 ggplot을 이용해 시각화합니다.
ggplot(world, aes(x = long, y = lat, group = group)) +
geom_polygon(aes(fill = LifeExpectancy)) +
scale_fill_gradient(low = "skyblue", high = "navy", name = "LifeExpectancy") +
labs(x = 'Longitude', y = 'Latitude',
title = 'Average Life Expectancy in the World')
scale_fill_gradient(low = "skyblue", high = "navy", name = "LifeExpectancy") : 열의 값에 따라 지도의 색상을 그라데이션으로 표현하며, 색상의 범위는 낮을수록 하늘색, 높을수록 남색으로 설정하고, 범례의 제목은 "LifeExpectancy"로 설정합니다.
- 실행 결과

지도를 봤을 때 아프리카 지역의 평균 기대 수명이 현저히 낮은 것으로 보아, 나라의 경제 수준과 기대 수명은 양의 상관관계가 있을 것이라고 판단됩니다.
④ 연도별 평균 기대 수명 변화 추이
이번엔 나라별이 아닌 연도별로 데이터를 나눠보겠습니다.
year_le = ds %>%
group_by(Year) %>%
summarise(avg = mean(LifeExpectancy))
year_leyear_le는 연도와 평균 기대 수명 칼럼으로 이루어진 리스트입니다.

이제 ggplot으로 시각화해보겠습니다.
ggplot(year_le, aes(Year, avg)) +
geom_line(col = 'steelblue', lwd = 1.5, lty = 2) +
labs(y = 'LifeExpectancy',
title = 'Average Life Expectancy in the World by Year')
- 실행 결과

cor(ds$Year, ds$LifeExpectancy)
그래프와 cor 함수를 이용한 상관계수를 참고하면 연도와 기대 수명은 양의 상관관계가 있다는 것을 알 수 있습니다.
데이터 제공
Sujay Kapadnis in Kaggle
'R' 카테고리의 다른 글
| [R] 다변량 자료 분석 (2) : Hotelling T^2 검정 (2) | 2024.03.21 |
|---|---|
| [R] 다변량 자료 분석 (1) : airquality 데이터 산점도 (0) | 2024.03.21 |
| [R] 데이터 전처리 및 시각화 (4) (0) | 2024.02.23 |
| [R] 데이터 전처리 및 시각화 (2) (1) | 2024.01.23 |
| [R] 데이터 전처리 및 시각화 (1) (1) | 2024.01.23 |



