반응형
이번 논문은 Meta에서 발표한 Segmentation 모델 SAM이다.
SA 프로젝트의 주요 구성 요소는 크게 Task, Model, Data로 나눌 수 있으며, 이번 포스팅에서도 이 세 가지를 중심으로 작성할 것이다.
1. Task
1.1. 배경
- 기존에는 특정 클래스를 학습해야 그 클래스에 대한 segmentation이 가능했었다.
- 근데 NLP에서는 Foundation Model이 강력한 제로샷, 퓨샷 일반화 능력을 보였는데,
- 여기서 영감을 받아 Segmentation 분야의 Foundation Model을 구축해보자는 아이디어로 Task를 정의함.
1.2. Promptable Segmentation Task
- 사용자가 제공하는 모든 종류의 프롬프트에 대해 하나 이상의 유효한 마스크를 반환하는 것.
- 여기서 말하는 프롬프트란 segmentation 하고자 하는 대상을 지정하는 모든 형태의 정보
- Whole, Part, Subpart 3가지 계층의 마스크를 예측함.

1.3. Pre-training
- 사전 학습 과정에서 모델은 각 학습 샘플(이미지 & 정답 마스크)을 입력받는다.
- 예를 들면, Point나 Box를 프롬프트로 주고, 모델이 그 프롬프트에 기반해서 예측한 마스크를, 실제 정답 마스크와 비교해서 loss를 계산하고 역전파를 해서 모델을 학습시키는 방식.
- 근데 이때 역전파는 minimum loss를 가진 마스크에 대해서만 수행하게 되는데, 그 이유는
- 3개 모두 역전파를 해버리면 최종 마스크를 예측할때 결국은 평균을 내버리기 때문에 part도 아니고 서브파트도 아니고 전체도 아닌 그냥 다 섞인 모호한 마스크가 나올 수 있기 때문.
- specialization: 매번 loss가 가장 낮은 하나만 업데이트함으로써 각 헤드들이 자기가 잘 잡아내는 계층을 더 잘 찾아내도록 학습이 되고, 나머지 헤드들은 파라미터 업데이트를 안 하고 패널티도 안 받으니까, 결론적으로 각 헤드가 전체, 파트, 서브파트를 각각 잘 잡아내도록 학습이 되는것이 목표.
- 이 방법은 기존의 interactive segmentation(충분한 수의 프롬프트 제공 필요)이랑 다르게 모호함을 포함한 모든 프롬프트에 대해 항상 유효한 마스크를 예측하도록 학습된다,
- 즉 하나의 프롬프트만 줘도 합리적인 마스크를 생성하도록 하는데 focus를 맞췄다.
1.4. Zero-shot Transfer
- 이렇게 학습된 모델은 어떤 프롬프트에 대해서도 일반화된 결과를 내놓을 수 있는 능력을 갖추게 되는데,
- 그렇게 되면 downstream task를 할때마다 fine-tuning 할 필요 없이 프롬프트 엔지니어링만으로도 문제 해결이 가능해진다.
- 예를 들면, 학습땐 본 적 없는 다른 도메인의 이미지도 적절한 프롬프트만 주면 잘 처리를 할 수 있다는 의미.
- 따라서 SAM은 컴퓨터비전 분야의 Foundation Model이 됐다. 라고 할 수 있음.
(추가) SAM 3의 Task
- SAM 1의 task는 시각적(Visual) 좌표에 초점을 맞췄다면, SAM 3는 Concept에 초점을 맞춤.
- 기존 프롬프트 point나 box 같이 시각적 좌표 뿐만 아니라 텍스트 설명이나 참조 이미지를 프롬프트로 줬을 때, 이미지나 영상에서 그 프롬프트에 제시된 객체를 알아서 찾아서 세그멘테이션 하는 개념.
- 간단하게 말하면 "점이나 박스를 찍으면 그걸 자른다"에서 "개념을 말하면 이미지나 영상에서 그 대상을 찾아서 자른다"로 task를 재정의함.
- The SAM2-to-SAM3 Gap in the Segment Anything Model Family: Why Prompt-Based Expertise Fails in Concept-Driven Image Segmentation
2. Model

2.1. 아키텍처 개요
- SAM은 크게 Image Encoder, Prompt Encoder, Mask Decoder 세 가지로 구성된다.
- Real time(실시간)을 살리기 위해 연산량이 많은 이미지 인코딩과 비교적 가벼운 프롬프트 처리 및 마스크 생성 과정을 분리한 것이 특징이다.
2.2. Image Encoder
- MAE(Masked AutoEncoder, https://arxiv.org/pdf/2111.06377)로 사전 학습된 ViT를 기반으로 한다.
- Image Embedding을 생성하며, 이미지당 한 번만 실행되는데, 그 이유는 한 번 생성해두면 이후 여러 프롬프트에 대해 재사용이 가능하므로, 추론 시간과 비용을 줄여 real time 작동이 가능하게 하기 때문이다.
2.3. Prompt Encoder
- 프롬프트를 Sparse와 Dense로 구분해서 Embedding 한다.
- Sparse Prompts: Point, Box, Text가 해당된다.
- Point, Box: Positional Encoding과 학습된 Embedding의 합산으로 표현.
- Text: CLIP의 텍스트 인코더를 활용해 Embedding
- Dense Promtps: 기존의 마스크(Mask)가 해당된다.
- Convolution Layer를 거쳐 이미지 임베딩과 동일한 해상도로 변환된 후, 이미지 임베딩과 요소별(Element-wise)로 합산된다.
2.4. Lightweight Mask Decoder
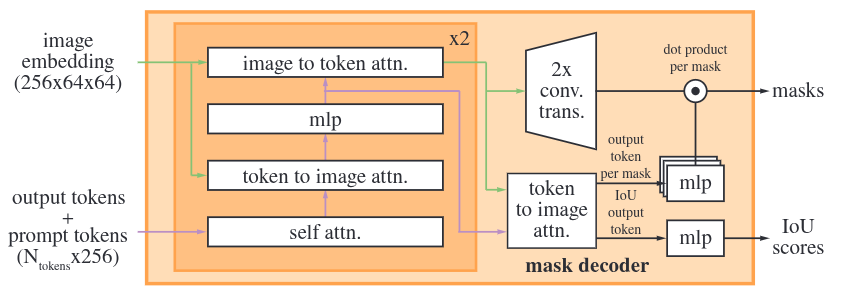
2.4.1. Input
- image embedding: Image Encoder에서 추출된 피처맵
- output tokens: 마스크 예측을 위해 모델이 학습한 output token.
- IoU score 예측용 토큰 1개 + 마스크 예측용 토큰 4개로 이루어진다.
- 이때 마스크 예측용 토큰 중 3개는 프롬프트가 모호할 때 Whole, Part, Subpart의 3가지 계층 마스크를 생성하는 데 사용되고,
- 나머지 하나는 여러 개의 프롬프트를 제공해서 모호함이 없는 상황일 때, 하나의 최적 마스크만을 출력하기 위해 추가된 마스크 토큰이다. (이 경우에는 위의 3개의 토큰은 작동하지 않고 네 번째 토큰만 작동함)
- prompt tokens: point, box 등 Prompt Encoder를 거친 임베딩 세트
2.4.2. Transformer Layer
- 프롬프트 임베딩과 이미지 임베딩이 서로 정보를 주고받는 레이어이다.
- 작동 순서:
- self attention
- prompt tokens와 output tokens 사이의 어텐션을 수행하여 프롬프트 간의 관계를 파악한다.
- token to image attention
- token은 Query, 이미지 임베딩이 Key-Value가 되어, 토큰이 이미지의 어느 위치를 참고해야 할지 결정한다.
- mlp
- mlp를 통과시켜 특징을 업데이트한다.
- image ro token attention
- 반대로 이미지 임베딩은 Query, token은 Key-Value가 되어, 프롬프트에 따라 이미지 임베딩을 업데이트한다.
- self attention
- 이 과정을 두 번 반복한다.
2.4.3. Upscaling 및 최종 어텐션
- 프롬프트 정보가 주입된 64 x 64 이미지 임베딩을 두 개의 Transposed Convolution Layer에 통과시켜 해상도가 4배 확장된 256 x 256 크기의 피처맵을 생성한다.
- 이와 동시에 token to image attention을 한번 더 수행하여 token을 최종 업데이트한다.
2.4.4. Mask & IoU Prediction
- 최종 업데이트된 4개의 mask tokens를 3개의 MLP에 통과시키고 Upscaling된 피처맵과 내적한다.
- 그 결과 256 x 256 크기의 마스크가 4개 생성된다.
- 최종 어텐션을 거치며 업데이트된 ioU token을 MLP에 통과시켜 Confidence Score(IoU Score)를 출력한다.
3. Data Engine
- SAM의 강력한 제로샷 성능은 11억개 이상의 마스크로 구성된 SA-1B 데이터셋으로 학습했기 때문이다.
- 논문에서는 이 데이터를 구축하기 위한 Data Engine과 최종 데이터셋의 특징을 강조한다.
3.1. Assised-manual stage
모델과 작업자가 협업하여 데이터셋을 확보하는 단계
- 공개된 dataset을 통해 SAM 학습
- 작업자가 객체/배경을 클릭하면 SAM이 실시간 마스크를 생성하는 방식
- 작업자들이 만든 새로운 마스크로 모델을 총 6번 재학습
- 그 결과, 작업 시간이 34초에서 14초로 감소, COCO 데이터셋 주석보다 3.5배 빠른 속도
- 이미지당 평균 마스크 수는 20개에서 44개로 증가
- 12만 개의 이미지에서 430만 개의 마스크 수 달성

3.2. Semi-automatic stage
모델이 아는 것은 건너뛰고 모르는 것만 작업자가 찾아내는 단계
- 모델이 자신 있어하는 마스크는 제외하고 모델이 놓친 객체들만 집중적으로 레이블링하는 방식이다.
- 신뢰도 높은 Mask가 표시된 이미지를 작업자에게 제공.
- 신뢰도는 bounding box detector을 활용
- 5회 재학습 추가 진행
- 그 결과, 작업 시간이 34초로 다시 증가함. (작고 어려운 객체들에 집중되어서)
- 이미지당 평균 마스크 수는 44개에서 77개로 증가
- 18만 개의 이미지에서 590만 개의 마스크를 추가로 확보


3.3. Fully automatic stage
- 이미지 전체에 (32 x 32) 점을 뿌리고 각 점마다 마스크 후보(whole, part, subpart)를 찾아냄
- IoU가 높고, 안정적인 마스크만 골라서 사용하고, 중복은 NMS(Non-Maximum Suppression)로 제거
- 작은 객체 인식률을 높이기 위해 crop 처리
- 1,100만 개의 이미지와 11억 개의 마스크 생성


3.4. SA-1B Dataset
- 데이터 엔진을 통해 구축된 최종 데이터셋
- 전 세계의 다양한 대륙과 국가의 데이터를 포함하여 지리적 편향을 줄임
- 모델이 생성한 마스크와 전문 작업자가 생성한 마스크와 비교했을 때 품질 면에서 큰 차이가 없다.


- 유럽(49.8%)과 아시아&오세아니아(36.2%)에서 높은 비율 차지
- 저소득 국가의 데이터는 1%도 채 되지 않는다.
- COCO와 O.I는 고소득 국가에 편중되어있는 반면, SA-1B는 비교적 균형 잡힌 분포이다.
- 성별, 나이대별, 피부톤별 유의미한 성능 차이는 없다.
- 다만, older vs middle 만 예외
이는 SAM이 공정하고 편향 없는 segmentation 성능을 보인다는 것을 입증한다.
반응형
'AI > NLP' 카테고리의 다른 글
| [12/09] 아이펠 리서치 15기 TIL | 미니 논문 작성 (1) | 2025.12.10 |
|---|---|
| [12/03] 아이펠 리서치 15기 TIL | InstructGPT | RLHF(Reinforcement Learning from Human Feedback) (0) | 2025.12.06 |
| [12/02] 아이펠 리서치 15기 TIL | Hugging Face Transformers (0) | 2025.12.04 |
| [11/28] 아이펠 리서치 15기 TIL | Transformer 기반 NLP # 1. Transfer Learning, Language Modeling, ELMo (1) | 2025.12.01 |
| [11/24] 아이펠 리서치 15기 TIL | Seq2Seq 영-한 번역기 만들기 (0) | 2025.11.27 |


