RFM 분석
고객의 구매 행동을 기반으로 충성도 높은 고객을 식별하고 마케팅 전략을 최적화하는 데 사용되는 데이터 분석 기법
RFM 분석의 세 가지 요소
- Recency (최신성): 고객이 마지막으로 구매한 날짜 (최근 구매일)
- Frequency (빈도): 고객이 특정 기간 동안 몇 번 구매했는지 (구매 횟수)
- Monetary (금액): 고객이 특정 기간 동안 총 얼마를 소비했는지 (구매 금액)
0. 패키지 불러오기
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.font_manager as fm
import datetime as dt1. 데이터 로드 및 전처리
(1) 데이터 로드
customer = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/코호트 분석/데이콘 이커머스/Customer_info.csv')
customer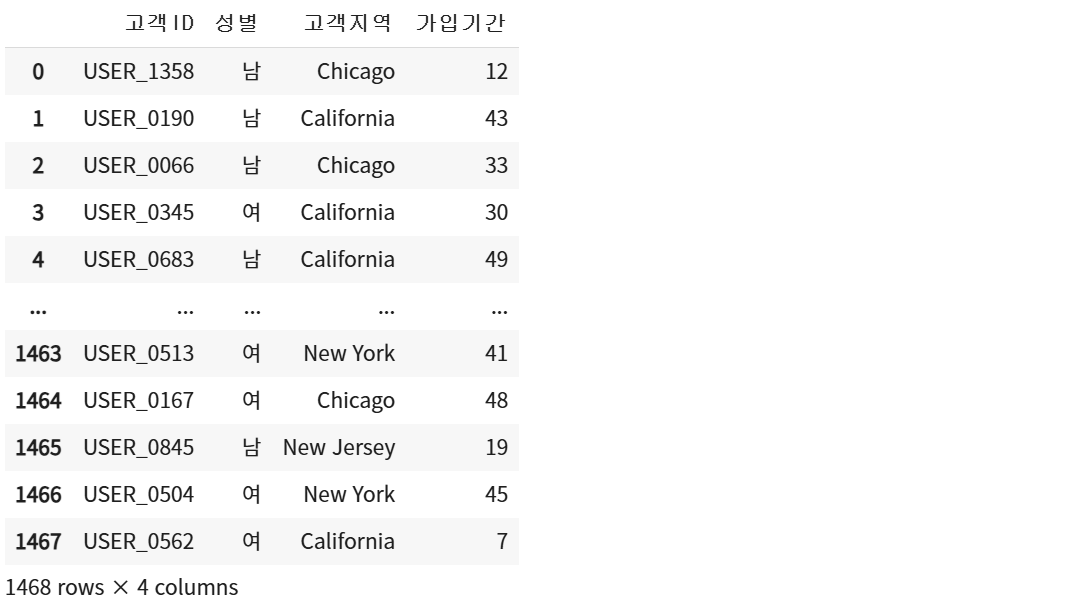
discount = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/코호트 분석/데이콘 이커머스/Discount_info.csv')
discount
marketing = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/코호트 분석/데이콘 이커머스/Marketing_info.csv')
marketing
onlinesales = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/코호트 분석/데이콘 이커머스/Onlinesales_info.csv')
onlinesales
tax = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/코호트 분석/데이콘 이커머스/Tax_info.csv')
tax
(2) 데이터 조인
할인율은 월별로 그룹화되어있지만,
다른 테이블과 조인할 칼럼이 제품 카테고리라서 같은 제품에 할인이 무작위로 들어갈 수 있다.
따라서 할인율은 마지막에 따로 칼럼을 만들 것임.
# 고객ID 기준으로 onlinesales 데이터와 customer 데이터 조인
df1 = onlinesales.merge(customer, on='고객ID')
df1
# 거래날짜(날짜) 변수 기준으로 df1과 marketing 데이터 조인
df2 = pd.merge(df1, marketing, how='inner', left_on='거래날짜', right_on='날짜')
df2 = df2.drop(columns = '거래날짜')
df2
# 제품카테고리 기준으로 tax 데이터도 조인
df = df2.merge(tax, on='제품카테고리')
df
(3) 할인율 계산
- 1, 4, 7, 10월의 할인율: 10%
- 2, 5, 8, 11월의 할인율: 20%
- 3, 6, 9, 12월의 할인율: 30%
# 날짜 열을 datetime 형식으로 변환
df['날짜'] = pd.to_datetime(df['날짜'])
# 할인율 계산 함수 정의
def calculate_discount_rate(row):
# 1. 쿠폰이 사용된 경우
# 날짜 변수의 월을 기준으로 계산
if row['쿠폰상태'] == 'Used':
month = row['날짜'].month
# 1, 4, 7, 10월의 경우 할인율 10% (0.1)
if month in [1,4,7,10]:
return 0.1
# 2, 5, 8, 11월의 경우 할인율 20% (0.2)
elif month in [2,5,8,11]:
return 0.2
# 3, 6, 9, 12월의 경우 할인율 30% (0.3)
else:
return 0.3
# 2. 쿠폰이 사용되지 않은 경우(Not Used, Clicked) 할인율 0
# Clicked는 쿠폰을 다운로드만 하고 사용하지는 않았다는 의미
else:
return 0
df['할인율'] = df.apply(calculate_discount_rate, axis=1)
df
2. R, F, M 변수 생성
(1) Recency
- 최근 거래 기준일 만들기
- 모든 고객의 거래 기록 중 가장 최근 구매일 선택
- 위 과정까지만 하면 R의 최소값이 0이 되는데, 이를 방지하기 위해 최소값을 1로 설정
recent_dt = df['날짜'].max() + pd.Timedelta(days=1)
(2) Monetary
- 구매금액 계산
- 구매금액 = 평균금액 * (1 - 할인율) * (1 - 세금) * 수량 + 배송료
df['구매금액'] = df['평균금액'] * (1-df['할인율']) * (1+df['GST']) * df['수량'] + df['배송료']
df
- 구매금액이 0 이하인 데이터가 있는지 확인하기
df[df['구매금액'] <= 0]
(3) Frequency
- F 계산을 위해 데이터를 고객ID 기준으로 정리
rfm_df = df.groupby('고객ID').agg({'날짜': lambda x: (recent_dt - x.max()).days,
'제품ID': 'count',
'구매금액': 'sum'})
rfm_df.columns = ['recency', 'frequency', 'monetary']
rfm_df
(4) 각 요소별 분포 시각화
import warnings
warnings.filterwarnings("ignore")
plt.figure(figsize = (15, 5))
plt.subplot(1,3,1)
sns.histplot(rfm_df['recency'], bins=20, color='coral', edgecolor='black')
plt.title('Recency (R) Distribution')
plt.subplot(1,3,2)
sns.histplot(rfm_df['frequency'], bins=20, color='skyblue', edgecolor='black')
plt.title('Frequency (F) Distribution')
plt.subplot(1,3,3)
sns.histplot(rfm_df['monetary'], bins=20, color='lightgreen', edgecolor='black')
plt.title('Monetary (M) Distribution')
plt.tight_layout()
plt.show()
- F와 M은 매우 편향된 경향을 보이는 반면 R은 비교적 고르게 분포하고 있음
- F는 0~100회 구간에 가장 많이 분포하고 있음
- M은 0~2만원 구간에 가장 많이 분포하고 있음
3. R, F, M 점수 설정 및 고객 세분화 작업
(1) 5개의 등급으로 간격 동일하게 점수 할당하기 (qcut 이용)
qcut
- 데이터를 분위수(quantile) 기준으로 균등한 개수의 그룹으로 분할
- 데이터를 특정 개수의 구간(bin)으로 나눌 때 적합
# R 값의 경우 수치가 커질수록 낮은 점수 부여 (수치가 크면 구매한 지 오래 됐다는 의미)
r_labels = list(range(5, 0, -1)) # Recency (최근성) 점수: 최근 방문한 고객이 높은 점수(5)
f_labels = list(range(1,6)) # Frequency (빈도) 점수: 자주 방문한 고객이 높은 점수(5)
m_labels = list(range(1,6)) # Monetary (구매 금액) 점수: 많이 구매한 고객이 높은 점수(5)
interval = 5
# r_cut: rfm_df['recency']를 같은 크기로 interval 개의 구간으로 나누는데 구간별 이름은 r_labels로 한다.
r_cut = pd.qcut(rfm_df['recency'], interval, labels = r_labels)
f_cut = pd.qcut(rfm_df['frequency'], interval, labels = f_labels)
m_cut = pd.qcut(rfm_df['monetary'], interval, labels = m_labels)
# rfm_df에 각각의 점수 할당
rfm_df = rfm_df.assign(R_score = r_cut, F_score = f_cut, M_score = m_cut)
(2) 고객 세분화를 위한 사용자 정의 함수 생성하기
def classify_customer_segment(row):
R, F, M = row['R_score'], row['F_score'], row['M_score']
if R == 5 and F == 5 and M == 5:
return 'Champion Customer' # 충성 고객
elif R >= 3 and F >= 3 and M >= 3:
return 'Potential Loyal Customer' # 잠재 고객
elif R >= 3 and F == 1 and M <= 2:
return 'New Customer' # 신규 고객
elif R <= 3 and F >= 3 and M >= 3:
return 'At Risk Customer' # 리스크 고객
elif R <= 2 and F >= 3 and M >= 2:
return 'Can’t Lose Customer' # 놓치지 말아야 할 고객
elif R <= 2 and 2 <= F <= 3 and 2 <= M <= 3:
return 'Dormant Customer' # 휴면 고객
elif R <= 2 and F <= 2 and M <= 2:
return 'Churned Customer' # 이탈 고객
else:
return 'Others'
rfm_df['Customer_Segment'] = rfm_df.apply(classify_customer_segment, axis=1)
(3) 고객 세분화 결과 시각화
# RFM_segmennt 시각화
plt.figure(figsize = (15, 7))
# segment 값을 기준으로 내림차순 정렬
seg_order = rfm_df['Customer_Segment'].value_counts().index
sns.countplot(data = rfm_df, x = 'Customer_Segment', color = 'skyblue', order = seg_order, edgecolor = 'black')
plt.xlabel('')
plt.ylabel('')
plt.rcParams['font.family'] = 'NanumGothic'
plt.title('Customer Segment')
plt.tight_layout()
plt.show()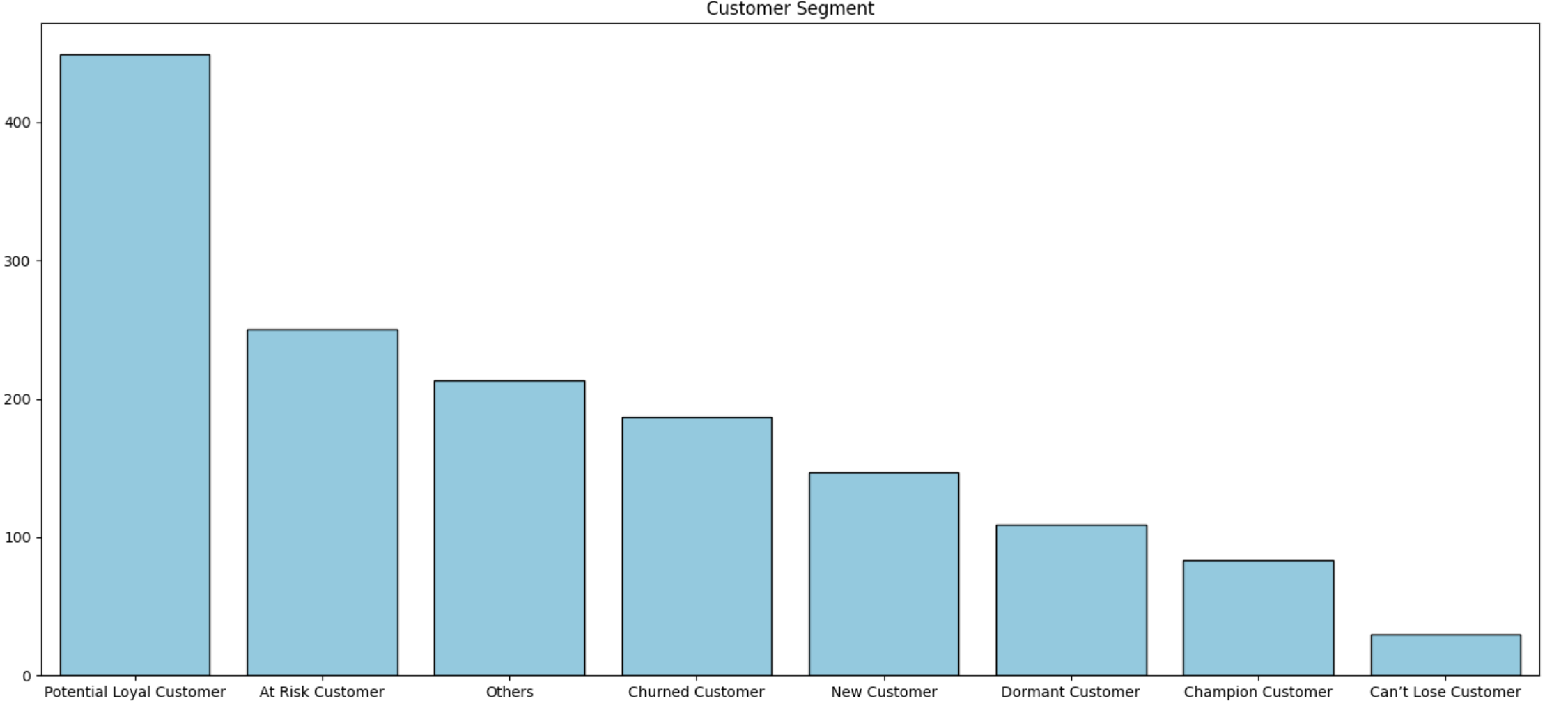
잠재 고객의 비중이 타 고객 평균 대비 2배 이상 높았고, 위험 고객, 기타, 이탈 고객, 신규 고객, 휴면 고객, 충성 고객, 놓치지 말아야 할 고객 순으로 비중이 높게 나타났다.
코호트 분석
재구매율 살펴보기
1. 각 사용자의 최초 구매한 월 연산
df
# 월별 Cohort를 수행하기 위해 데이터 세트의 Month에 YYYY-MM형식의 데이터 세트를 입력
df['Month'] = df.날짜.apply(lambda x: x.strftime('%Y-%m'))
# MonthStarted라는 사용자의 첫 구매가 발생한 연도-월 칼럼 추가
df.set_index('고객ID', inplace = True)
df['MonthStarted'] = df.groupby(level=0)['날짜'].min().apply(lambda x: x.strftime('%Y-%m'))
df.reset_index(inplace=True)2. 첫 구매 월과 가장 최근 구매 월의 차이 계산
# Month와 MonthStarted 열을 datetime 형식으로 변환
df['Month'] = pd.to_datetime(df['Month'])
df['MonthStarted'] = pd.to_datetime(df['MonthStarted'])
# 각 구매가 최초 구매로부터 얼마의 월이 지났는지 연산한 MonthPassed 열 추가
df['MonthPassed']=(df['Month'].dt.year-df["MonthStarted"].dt.year)*12 +\
(df['Month'].dt.month-df['MonthStarted'].dt.month)
df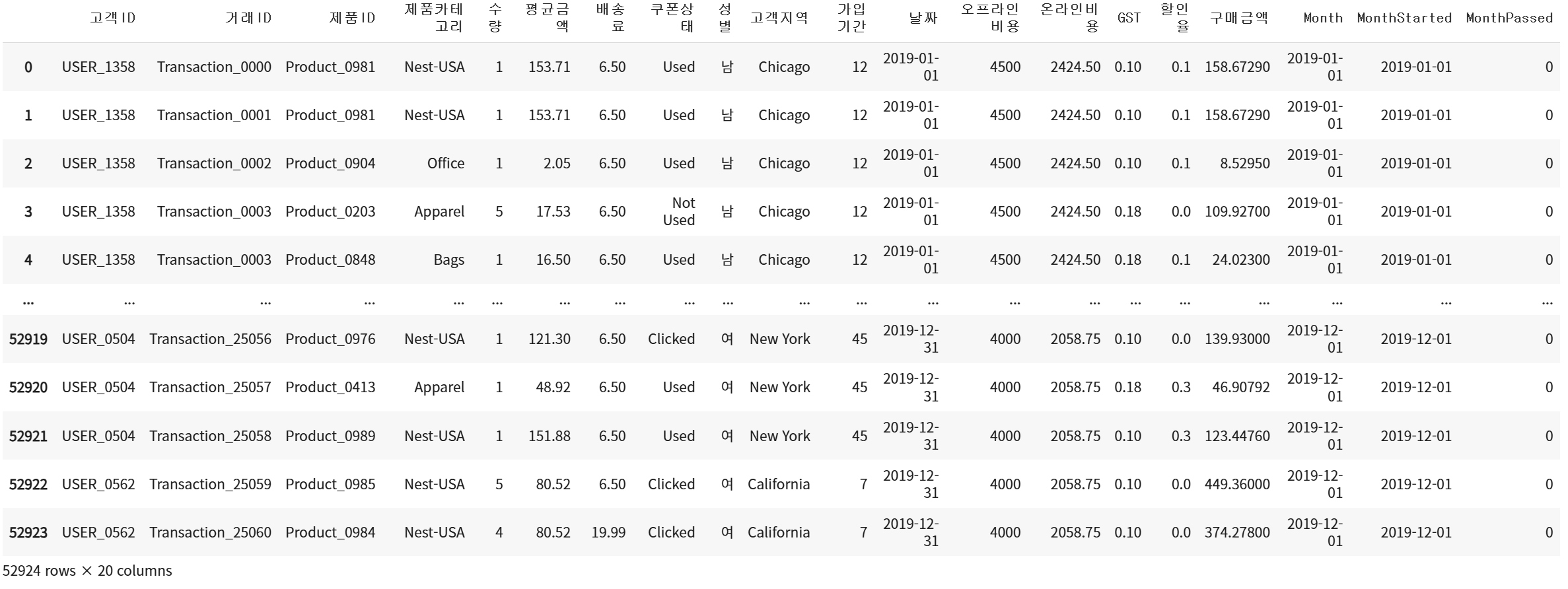
3. 최초 구매 월, MonthPassed를 기준으로 고객 카운팅
def get_unique_no(x):
return len(np.unique(x))
cohort_group = df.groupby(['MonthStarted', 'MonthPassed'])
cohort_df = cohort_group['고객ID'].apply(get_unique_no).reset_index()
cohort_df
4. 피벗 테이블 생성
cohort_df = cohort_df.pivot(index='MonthStarted', columns='MonthPassed')
cohort_df
비율로 변환
customer_cohort = cohort_df.div(cohort_df.iloc[:, 0], axis=0)*100
customer_cohort = customer_cohort.round(decimals=2)
customer_cohort
5. 재구매율 Heatmap 시각화
xticks = np.arange(0, 12)
yticks = ['2019/01', '2019/02', '2019/03', '2019/04', '2019/05', '2019/06', '2019/07', '2019/08', '2019/09', '2019/10', '2019/11', '2019/12']
plt.figure(figsize=(15, 8))
sns.heatmap(customer_cohort,
annot=True,
xticklabels=xticks, # Change xticklabels to yticks
yticklabels=yticks,
fmt='.1f')
plt.xlabel('코호트 기간')
plt.ylabel('첫구매월')
plt.show()
분포 해석
- 6월 코호트의 경우, 1개월 차 14.6%, 2개월 차 16.1%로 다른 코호트보다 높은 재방문율을 보인다. 이는 해당 시기에 특별한 마케팅 전략이 있었을 가능성을 시사한다.
- 3월 코호트 역시 1개월 차 10.2%, 2개월 차 19.8%에서 높은 재방문율을 보인다.
5~8월 기간에 재방문율이 높은 것으로 나타남.
- 계절적 요인
- 5~8월은 여름 시즌으로, 특정 업종(예: 여행, 패션, 스포츠, 아웃도어, 식음료 등)에서 소비가 증가하는 시기일 수 있다.
- 특히 여름 세일, 휴가 시즌, 여름맞이 프로모션 등의 영향으로 인해 재방문율이 높아질 가능성이 있다.
- 마케팅 및 프로모션 효과
- 특정한 마케팅 캠페인, 할인 행사 등의 요인이 있을 수 있다.
- 재방문 유도 프로모션 (예: 첫 구매 후 일정 기간 내 재구매 시 추가 할인 제공)
결론 및 인사이트
- 5~8월의 높은 재방문율은 다양한 요소(계절성, 마케팅, 특정 제품군 등)에 의해 발생할 수 있다.
- 여름 시즌 특수를 고려하여 맞춤형 프로모션을 더울 강화하고, 재방문 고객을 충성 고객으로 전환하는 전략을 수립이 필요하다.
- 성공적인 마케팅 캠페인이 있었다면, 해당 전략을 연중 반복하거나 다른 시즌에도 응용하여 효과를 극대화할 수 있다.
- 반대로, 이 시기에 경쟁사 대비 강점을 보였는지 분석하고, 장기적으로 유지할 방법을 고민해야 한다.
데이터 제공: https://dacon.io/competitions/official/236222/data
이커머스 고객 세분화 분석 아이디어 경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
'Python' 카테고리의 다른 글
| [Python] 이커머스 데이터 퍼널 분석(Funnel Analysis) (0) | 2025.02.16 |
|---|---|
| [Python] 결측치 보간법 (1/2차 선형보간법, 평균대치법, KNN, MICE) (0) | 2024.05.29 |
| [Python] 이상치 탐지 기법 (IQR, Isolation Forest, rolling 함수, decompose 패키지) (0) | 2024.05.11 |


